An important step in the soundness analysis of the FRI-IOPP is bounding the probability of an “unlucky fold”: assuming that the prover is cheating (so that the initial oracle is $\delta$-far from the code), how likely is it that the verifier “unluckily” chooses a folding challenge $\alpha \in \ff$ such that the $\alpha$-folding of the oracle is not $\delta$-far from its code? We describe here how to bound this probability using the Correlated Agreement Theorem from [PG-RSC].
Notation
Let $\ff$ be a finite field and suppose $\Omega \subset \ff^\times$ is a multiplicative subgroup with even order, so that $\omega \mapsto \omega^2$ is a 2-to-1 map $\Omega \to \Omega^2$. Write $\ffOmega$ (resp. $\ffOmegaSqrd$) for the space of all $\ff$-valued functions on $\Omega$ (resp. $\Omega^2$). Denote by $\eval_\Omega$ the evaluation map $f \mapsto (f(\omega))_{\omega \in \Omega} \in \ffOmega$, and for any $d > 0$, write $\RSd = \eval_\Omega (\fxd)$ for the Reed-Solomon code consisting of evaluations of polynomials with degree less than $d$ on $\Omega$. Write $\Delta$ for the relative Hamming distance.
Define $\Theta = (\Theta_0, \Theta_1): \ffOmega \to \ffOmegaSqrd \times \ffOmegaSqrd$ by $$ (\Theta_0 u)_{\omega^2} = \frac{u_\omega + u_{-\omega}}{2}, \qquad (\Theta_1 u)_{\omega^2} = \frac{u_\omega – u_{-\omega}}{2\omega}, \qquad \forall \omega \in \Omega,\ \forall u \in \ffOmega.$$ The map $\Theta$, which operates in the evaluation domain, corresponds to the familiar even/odd decomposition of a polynomial in the coefficient domain. In particular: $$u_\omega = (\Theta_0 u)_{\omega^2} + \omega (\Theta_1 u)_{\omega^2}, \qquad \forall \omega \in \Omega,\ \forall u \in \ffOmega,$$ and so the folding $\Psi_\alpha u$ of $u \in \ffOmega$ using $\alpha \in \ff$ can be defined using $\Theta$ via: $$ \Psi_\alpha : \ffOmega \to \ffOmegaSqrd, \qquad u \mapsto (\Theta_0 u) + \alpha (\Theta_1 u), \qquad \forall u \in \ffOmega.$$
The “Correlated Agreement Theorem” $\mathrm{CAT}_{d, \Omega}$
Let $\rho = d/|\Omega|$, and write $\mathrm{CAT}_{d, \Omega}$ for the following statement, proven in [PG-RSC] (as Theorem 4.1): Suppose that $\delta \in (0, \frac{1 – \rho}{2}]$, and that $\uZero, \uOne \in \ffOmega$ are such that $$ |\ \{ \alpha \in \ff \ |\ \Delta (\uZero + \alpha \uOne, \RSd) < \delta \}\ | \geq |\Omega|.$$ Then there exists $\Lambda \subset \Omega$ with $\frac{|\Lambda|}{|\Omega|} \geq 1 – \delta$ and $\fZero, \fOne \in \fxd$ such that $$ \fZero(\lambda) = \uZero_\lambda, \qquad \fOne(\lambda) = \uOne_\lambda, \qquad \forall \lambda \in \Lambda.$$
The Correlated Agreement Theorem & Unlucky Folds
The contrapositive of $\mathrm{CAT}_{d/2, \Omega^2}$ can be used to bound the probability of an unlucky fold as follows.
Assume that $u \in \ffOmega$ is $\delta$-far from $\RSd$. Then $$ \Delta(u, \eval_\Omega f) \geq \delta, \qquad \forall f \in \fxd.$$ Suppose (for contradiction) that there exist $\fZero, \fOne \in \fxdHalf$ and $\Lambda \subset \Omega^2$ with $|\Lambda| / |\Omega^2| \geq 1 – \delta$ and $$ \fZero (\lambda) = (\Theta_0 u)_\lambda, \qquad \fOne (\lambda) = (\Theta_1 u)_\lambda, \qquad \forall \lambda \in \Lambda.$$ Set $f(X) = \fZero(X^2) + \fOne(X^2)$ and write $\sqrt \Lambda = \{ \omega \in \Omega \ | \ \omega^2 \in \Lambda \}$. Then for any $\lambda \in \Lambda$ and either of its two square roots $\omega \in \sqrt \Lambda$: $$ f(\omega) = \fZero(\lambda) + \omega \fOne(\lambda) = (\Theta_0 u)_\lambda + \omega (\Theta_1 u)_\lambda = u_\omega,$$ and so $f \in \fxd$ and $u \in \ffOmega$ agree on a subset $\sqrt \Lambda \subset \Omega$ of density $$ \frac{|\sqrt \Lambda|}{|\Omega|} = \frac{|\Lambda|}{|\Omega^2|} \geq 1 – \delta.$$ Thus we would have that $\Delta(u, \eval_\Omega f) < \delta$, which would contradict the $\delta$-farness of $u$ from the code. Thus no such $\fZero$, $\fOne$ and $\Lambda$ exist. Therefore, by the contrapositive of $\mathrm{CAT}_{d/2, \Omega^2}$, we have that $$ |\ \{ \ \alpha \in \ff \ |\ \Delta (\Theta_0u + \alpha \Theta_1 u, \RSdHalf) < \delta \ \}\ | < |\Omega|.$$ i.e. that the probability of the folding $\Psi_\alpha u$ failing to be $\delta$-far from $\RSdHalf$ (an “unlucky fold”) is strictly less than $\epsilon = \frac{|\Omega|}{|\ff|}$.
Proving the Correlated Agreement Theorem
The Correlated Agreement Theorem, in the case where $\delta$ is at most the unique decoding radius, can be proven by running the Berlekamp-Welch decoder over the function field $\ff (\alpha)$ (where $\alpha$, transcendental over $\ff$, stands in for the folding challenge). This works since the Berlekamp-Welch decoder is really just a result from linear algebra, and so works over any field. The other ingredient is the Polishchuk-Spielman Lemma. A proof of the theorem and this lemma are given in [PG-RSC].
References
[PG-RSC]: E. Ben-Sasson, D. Carmon, Y. Ishai, S. Kopparty and S. Saraf, “Proximity Gaps for Reed–Solomon Codes,”, 2020 (pdf).
(inspired by discussions with my colleagues Giorgos Zirdelis & Vishruti Ganesh; any mistakes are my own).
Consider the case of multiplication in 2-of-3 Shamir secret sharing. The goal is to compute the product of two secrets $a, b$; the parties should learn the product $ab$, but learn nothing else about $a$ and $b$ than couldn’t already have been deduced from $ab$. After each party computes the product of its shares locally, they possess (in a sense) 3-of-3 Shamir shares of the product $ab$. As we’ll see below, however, if the parties reveal their shares without first re-randomizing, then information about the original secrets is leaked. Indeed, one of the parties is guaranteed to be within one bit of full knowledge of $a$ and $b$.
We wish to compute the product of two secrets $a, b$ in 2-of-3 Shamir. Write $\alpha_i$ for evaluation point corresponding to the $i$th party for $i=1,2,3$ (three distinct values). For simplicity, let’s store the secret as the constant term of the polynomial (so assume $0 \ne \alpha_i$ for all $i$). So the dealer chooses two random polynomials $p, q$ such that $$ p(0) = a,\quad q(0) = b, \quad \text{deg}(p) < 2, \quad \text{deg}(q) < 2.$$Note that, because of the degree bound, these polynomials have only one root each! For all $i$, the $i$th party takes its share $p(\alpha_i)$ of $p$ and $q(\alpha_i)$ of $q$ and multiplies them locally, obtaining $(pq)(\alpha_i)$. Assume that the parties now reveal their shares $(pq)(\alpha_i)$. Then the product polynomial $pq$ can be interpolated (since it is quadratic, and there are 3 parties, so 3 evaluations). So each of the parties now know $pq$. Since $pq$ is a product of two linear polynomials, it has two roots, say $\beta$ and $\gamma$ (not necessarily distinct). Each party can compute these roots from $pq$. By uniqueness of factorization, either $\beta$ is a root of $p$ and $\gamma$ a root of $q$, or vice versa. Since there are 3 evaluation points and only two roots, we can choose $i$ such that $\alpha_i \ne \beta, \gamma$. Then party $i$ is only 1 bit of information away from full knowledge of the values of the secrets $a, b$:
if $\beta$ is a root of $p$, then party $i$ knows two distinct points $(\beta, 0)$, $(\alpha_i, p(\alpha_i))$ on the graph of $p$, and this fully determines $a$; $\gamma$ is then a root of $q$, and in a similar fashion $b$ is also determined.
if instead $\gamma$ is a root of $p$ (and so $\beta$ is a root of q) then the values of $a$ and $b$ are similarly fully determined.
It’s either one, or the other! That’s why party $i$ is “1-bit short” of full knowledge.
“How to Prove False Statements: Practical Attacks on Fiat-Shamir” (Khovratovich, Rothblum, Soukhanov; 2025) constructs families of circuits for which the GKR protocol, when made non-interactive by Fiat-Shamir heuristic, will prove false statements. It’s a great paper and is so well written that I won’t attempt to do better by paraphrasing their constructions. What I’d like to look at here is instead the consequences of the result for real-world applications of non-interactive proofs.
The Fiat-Shamir heuristic attempts to simulate, in the non-interactive setting, random challenges that the verifier would have issued in an interactive setting. It does so by replacing the information-theoretic assumption of the random oracle model with a cryptographic assumption about deterministic hash functions. Fiat-Shamir is crucial to real-world cryptographic applications (and blockchains, in particular) because it enables non-interactive proofs: a non-interactive proof can be checked by any number of verifiers, present and future. Moreover these verifiers don’t need to trust one another. They can check the validity of the proof for themselves.
How does Fiat-Shamir work? The prover (and any future verifiers), replace each random message from the verifier with the result of applying a cryptographic hash function to all of the messages from the prover up to that point. Intuitively, the cryptographic assumptions on the hash function should then prevent a computationally-bounded malicious prover from choosing their messages to obtain a desired (Fiat-Shamir generated) message from the verifier and thereby prove a false statement. This has never been proven, however, and indeed earlier work had demonstrated somewhat contrived protocols where it fails.
The current paper shows that the Fiat-Shamir heuristic fails for the very natural and useful GKR protocol. In my assessment, this paper is very impactful in a social sense, in that it reminds us all of the fallibility of cryptographic conjectures. It is a blow to the confidence of those building blockchain applications, and also to those who use blockchains as a store of wealth. However, this is not because this specific attack can be carried out in meaningful applications, but simply because it reminds us how we tend to build castles on sand. Moreover, the result “breaks the promise” of GKR in that it illustrates how GKR can, for certain maliciously constructed circuits, prove false statements. Importantly, however, the paper demonstrates failure of non-interactive GKR only for a contrived family of circuits, and so there is a strong sense in which this result has no practical consequences whatsoever. A verifying party is not simply checking “is this a valid proof of the satisfaction of some circuit?” but rather “is this a valid proof of satisfaction of the circuit XYZ known to me”. Any verifying party that doesn’t care which circuit is satisfied before it releases the funds (or performs some critical function) was already vulnerable to deception, irrespective of this result. Why would you trust a circuit that you hadn’t audited?
It has also been suggested that this paper signals the end of recursive verification of GKR circuits. The reason for this being that both this attack and recursive verification rely on being able to circuitize the hash function used in the transcript, and so facilitating one facilitates the other. This concern evaporates however when we again remember that the only circuits used in production are ones upon which the prover and verifying parties have agreed, and this includes circuits for recursive verification. Why would a verifying party accept the use of a recursive verifier circuit with a backdoor in it? They simply wouldn’t.
$\newcommand{\fxd}[0]{\mathbb{F}[X]^{< d}} \newcommand{\fxdone}[0]{\mathbb{F}[X]^{< d-1}} \newcommand{\RS}[0]{\mathrm{RS}} \newcommand{\drc}[0]{\mathrm{D}_{r, c}\,} \newcommand{\fo}[0]{\ff^\Omega} \newcommand{\eval}[0]{\mathrm{E}}$ Here we cover how to build a polynomial commitment scheme (PCS) from the FRI interactive oracle proof of proximity (FRI-IOPP). Specifically, we explain how to reduce an evaluation proof to a proof of proximity. It is assumed that the reader already understands the FRI-IOPP. Everything here was derived from reading Transparent PCS with polylogarithmic communication complexity (Vlasov & Panarin, 2019), along with (to be honest) much reflection and discussion.
We assume the usual setup for FRI. Let $\ff$ denote a finite field, write $\Omega \subset \ff$ for a subgroup of the group of units $\ff^\times$ with $|\Omega|$ a power of two. Let $\fo$ denote the vector space of functions $\Omega \to \ff$, considered as vectors with entries indexed by some fixed enumeration of $\Omega$ (we’ll call elements of $\fo$ “words”). Let $\eval: \fx \to \fo$ denote the evaluation map, i.e. $$ (\eval f)_\omega = f(\omega) \quad \forall f \in \fx \quad \forall \omega \in \Omega.$$ Write $\Delta$ for the relative Hamming distance on $\fo$, and let $\RS_k = \eval (\fx^{< k}) \subset \fo$ denote the Reed-Solomon code with degree bound $k$. Fix throughout some degree bound $1 < d < |\Omega|$. We will be concerned with two separate Reed-Solomon codes, namely $\RS_d$ and $\RS_{d-1}$ (note that both use the same evaluation points $\Omega$). Write $\delta_0$ for the unique decoding radius of $\RS_d$, i.e. $\delta_0$ is maximal such that, for any $f \in \fxd$ and $u \in \fo$, $$ \Delta(u, \eval f) \leqslant \delta_0 \implies \left( \ \forall g \in \fxd \quad \Delta(u, \eval g) \leqslant \delta_0 \implies f = g \ \right).$$
The data of a commitment in the FRI-PCS with degree bound $d$ is a word $u \in \fo$ (more precisely: an oracle to $u$). Assume for now that the prover is honest. In the simplest case, $u = \eval f$ for some $f \in \fxd$. Crucially, however, we require something weaker than this of a commitment $u$: it is sufficient that $u$ be within the unique decoding radius of some codeword $\eval f$, i.e. $$\begin{equation}\label{UDR}\tag{UDR} \Delta (u, \eval f) \leqslant \delta_0 \quad \exists f \in \fxd.\end{equation}$$ Any such $u$ is considered to be a valid commitment to its corresponding $f \in \fxd$. Why is this subtlety necessary? Because if the stricter condition $u = \eval f$ were required, then the (soon to be explained) reduction of an evaluation proof to an invocation of the FRI-IOPP wouldn’t be possible. The FRI-IOPP isn’t sufficiently sensitive to reliably distinguish between a codeword and nearby non-codewords (for an explicit demonstration, see here).
Assuming that the prover has sent a commitment $u \in \fo$ to the verifier, an evaluation proof proceeds as follows. The verifier chooses an evaluation point $r \in \ff \setminus \Omega$ and sends this to the prover, and the prover responds with the purported evaluation $c$ of the polynomial committed to (in the case of an honest prover, $c = f(r)$ where $f$ is determined by \eqref{UDR}). The prover wants to establish $$\begin{equation}\label{TwoPart}\tag{TwoPart} \exists f \in \fxd \quad \st \quad \Delta(u, \eval f) \leqslant \delta_0 \ \ \text{and} \ \ f(r) = c.\end{equation}$$ Since $f(r) = c$ if and only if $f-c$ is divisible by $X-r$, and degree is additive under polynomial multiplication, this two part claim is equivalent to the following unified claim: $$\begin{equation}\label{Unified}\tag{Unified} \exists q \in \fxdone \quad \st \quad \Delta(u, \eval ((X-r)q + c)) \leqslant \delta_0.\end{equation}$$ Thus we are interested in the proximity of the commitment $u$ to a specific subset of $\RS_d$, namely the subset consisting of codewords of the form $\eval ((X-r)q + c)$. Note, however, that we can not immediately apply FRI-IOPP to establish this claim, since this subset is not itself a Reed-Solomon code (it isn’t even a linear subspace of $\fo$). The good news is that, with a small amount of work, it can be seen that the claim \eqref{Unified} is equivalent to a claim that can be established using the FRI-IOPP (with degree bound $d-1$). This claim involves a vector $\drc u \in \fo$ derived from $u$, which we’ll define below. And thus the FRI-PCS evaluation proof will be established using by a proximity proof!
Firstly, a note on oracles. Importantly, the verifier does not need to receive or read all of the $u \in \fo$ that commits to $f \in \fxd$. Since an evaluation proof reduces to an invocation of the FRI-IOPP, it is sufficient for the verifier to be supplied with a mechanism to query entries $u_\omega$ of $u$ at arbitrary indices $\omega \in \Omega$. In an information theoretic presentation, this mechanism is abstracted as an oracle. In implementation, the oracle is typically instantiated with a Merkle commitment to the tree whose leaves are the $u_\omega$ (enumerated in some agreed upon manner). The prover binds itself to $u$ by sending the Merkle root to the verifier, and the verifier queries an entry $u_\omega$ by asking the prover for the Merkle path from the root to the corresponding leaf.
Let’s now derive the reduction of the evaluation proof to an instance of the FRI-IOPP. Given bijections $\theta_w : \ff \to \ff$ for each $\omega \in \Omega$, a bijection $\theta : \fo \to \fo$ of the space of all words can be defined by $$(\theta v)_\omega = \theta_\omega (v_\omega) \quad \forall v \in \fo,\quad \forall \omega \in \Omega.$$ Call such a map $\theta$ a “component-wise bijection”; it is immediate for any such map that $$\begin{equation}\label{HDInv}\tag{HDInv} \Delta(\theta u,\ v) = \Delta(u,\ \theta^{-1} v) \quad \forall u, v \in \fo.\end{equation}$$ For any $r \in \ff \setminus \Omega$ and $c \in \ff$, define a component-wise bijection $\drc: \fo \to \fo$ by $$ (\drc u)_\omega = \frac{u_\omega – c}{\omega – r} \quad \forall u \in \fo, \quad \forall \omega \in \Omega.$$ Its inverse is given by $$ (\drc^{-1} (v))_\omega = (\omega – r) v_\omega + c \quad \forall v \in \fo, \quad \forall \omega \in \Omega,$$ from which it follows immediately that $$\begin{equation}\label{DrcInverse}\tag{DrcInverse} (\drc^{-1} \circ \eval) (q) = \eval ( (X-r) q + c) \quad \forall q \in \fx.\end{equation}$$ Combining \eqref{HDInv} and \eqref{DrcInverse}, we obtain $$\begin{equation}\label{StepDown}\tag{StepDown} \Delta(\drc u,\ \eval (q)) = \Delta(u,\ \eval((X-r)q + c)) \quad \forall v \in \fo \quad \forall q \in \fx,\end{equation}$$ and substituting this into the claim \eqref{Unified}, we obtain the equivalent claim $$\begin{equation}\label{FRIable}\tag{FRIable} \exists q \in \fxdone \quad \st \quad \Delta(\drc u, \eval q) \leqslant \delta_0,\end{equation}$$ which the prover and verifier can establish using the FRI-IOPP! \eqref{FRIable} is nothing more than the statement that $\drc u$ is $\delta_0$-close to $\RS_{d-1}$.
Cheating fails (w.h.p.)
It is instructive to now consider the two possible cheating strategies for the prover in this reduction to the FRI-IOPP. The first is where the first claim of \eqref{TwoPart} doesn’t hold, i.e. for all $f \in \fxd$, $u$ is not within the unique decoding radius of some $\eval f$. Put differently, this is just saying that $\Delta(u,\ \RS_d) > \delta_0$, i.e. “$u$ is $\delta_0$-far from the code $\RS_d$”. Thus, by \eqref{StepDown}, for any $q \in \fxdone$, $$ \Delta(\drc u,\ \eval q) = \Delta(u,\ \eval ((X-r)q + c)) \geqslant \Delta(u,\ \RS_d) > \delta_0,$$ and so claim \eqref{FRIable} is false, and will be caught with the soundness bound of the FRI-IOPP. The only other cheating strategy for the prover is that where the $u$ is in the unique decoding radius of $\eval f$ for some $f \in \fxd$, but the claimed evaluation is false, i.e. $f(r) \ne c$. Then for any $q \in \fxdone$, we have $f \ne (X-r)q + c$ (since otherwise the evaluations at $c$ would match), and so $\eval f$ and $\eval ((X-r)q + c)$ are distinct codewords. Thus, by \eqref{StepDown}, $$\Delta(\drc u,\ \eval q) = \Delta(u,\ \eval ((X-r) q + c)) > \delta_0,$$ since $u$ can be within $\delta_0$ (the unique decoding radius) of at most one codeword (which is $\eval f$).
How to perform the FRI-IOPP with degree $d-1$?
The FRI-IOPP is defined for degree bounds $d$ that are powers of two. But if $d$ is a power of two, how to perform the second FRI-IOPP, which uses the degree bound $d-1$? The short answer is simply to replace it with another invocation of the FRI-IOPP with degree bound $d$. In detail:
The verifier will use the oracle to $u$ to simulate an oracle $\drc u$ to $(f-c)/(X-r)$.
The prover wishes to establish that $\drc u$ is within the unique decoding radius (UDR) of $\RS_{d-1}$. The UDR for $\RS_{d-1}$ is larger than the UDR $\delta_0$ for $\RS_d$, so it is sufficient to show that $\Delta(\drc u,\ \RS_{d-1}) < \delta_0$.
Prover and verifier use the FRI-IOPP to instead show that $\Delta(\drc u,\ \RS_d) < \delta_0$. This shows that there exists some $q \in \fxd$ such that $\Delta(\drc u,\ \eval q) < \delta_0$.
By equation \eqref{StepDown}, it follows that $\Delta(u,\ (X-r)q + c) < \delta_0$.
But we are within the UDR, so $(X-r)q + c = f$, where $f$ is the polynomial from the first IOPP invocation. Thus $\text{deg}(q) = \text{deg} (f) – 1$. The first FRI-IOPP showed that $\text{deg} (f) < d$, and so $\eval q \in \RS_{d-1}$. Thus \eqref{Unified} is established, and we are done.
Let $\mathbb{F}$ be a finite field, and write $\mathbb{F}[X]^{< n}$ for the polynomials of degree less than $n$ over $\mathbb{F}$. For any $\omega \in \mathbb{F}^n$, write $$ \epsilon_\omega: \mathbb{F}[X]^{< n} \to \mathbb{F}^n \qquad f \mapsto (f(\omega_i))_{i=1, \dots, n} \quad \forall f$$ for the evaluation map. For any such choice of $n, \omega$ and of $0 < k \leqslant n$, let $$ RS_{n,k}[\omega] := \epsilon_\omega (\mathbb{F}[X]^{< k})$$ denote the corresponding Reed-Solomon code. We’ll require that the entries of $\omega$ are distinct, so that $RS_{n,k}[\omega]$ is a $k$-dimensional subspace of $\mathbb{F}^n$ and hence is a $(n,k)$ linear code. The ambient space $\mathbb{F}^n$ is considered to be equipped with a fixed basis, and comparison of the coefficients of two vectors with respect to this basis defines the Hamming distance.
Equivalences of linear codes
Recall that two $(n,k)$ linear codes are equivalent if there exists a linear isomorphism $\mathbb{F}^n \to \mathbb{F}^n$ that preserves the Hamming distance on the ambient and maps the codes to one another. Expressed with respect to the fixed bases, an equivalence of codes is a matrix with precisely one non-zero entry in each row and column.
Equivalences of Reed-Solomon codes
The construction of a Reed-Solomon $RS_{n,k}[\omega]$ code depends on the choice of evaluation points $\omega$ – but to what extent does it really matter which $\omega$ is chosen? It is easy to see that it doesn’t always matter. For instance, permuting the entries of $\omega$ gives an equivalent code. A more interesting example: if $\lambda \in \mathbb{F}^\times$, then $RS_{n,k}[\lambda \omega] = RS_{n,k}[\omega]$, i.e. the two codes are coincide. To see this, just notice that any polynomial $f(X)$ has the same degree as $f(\lambda^{-1}X)$, and that $\epsilon_\omega (f(X)) = \epsilon_{\lambda \omega} (f(\lambda^{-1}(X)))$. Hence the codes coincide. This example generalizes immediately to invertible affine transformations of $\mathbb{F}$ applied to coordinate-wise to $\omega$.
Non-equivalent $(n, k)$-Reed-Solomon codes
There are choices of $\omega$ that lead to non-equivalent $RS_{n,k}[\omega]$, but this seems difficult to verify manually. A computational approach is to use Sage to compute the automorphism groups (i.e. group of self equivalences) of $RS_{n,k}[\omega]$ for various $\omega$. Equivalent codes must have isomorphic automorphism groups. So it is sufficient to find two choices of $\omega$ such that the automorphism groups of the associated code $RS_{n,k}[\omega]$ have distinct orders. For example:
Hence the $\mathbb{F_7}$-linear codes $RS_{4, 2}[(0, 1, 2, 3)]$ and $RS_{4, 2}[(0, 1, 2, 4)]$ are not equivalent.
Generalized Reed-Solomon codes
In order to find further examples of equivalences of Reed-Solomon codes, it turns out to be helpful to describe what at first appears to be a more general construction, but is in fact (up to equivalence of codes) simply a re-parameterization of the same objects. For $\omega \in \mathbb{F}^n$ with distinct entries and $\alpha \in (\mathbb{F}^\times)^n$, let $$\epsilon_{\omega, \alpha}: \mathbb{F}[X]^{<n} \to \mathbb{F}^n \quad f \mapsto (\alpha_i f(\omega_i))_{i=1, \dots, n} \quad \forall f.$$ Then $\epsilon_{\omega, \alpha}$ is linear, and the image of $\mathbb{F}[X]^{<k}$ under this map is the generalized Reed-Solomon code $GRS_{n,k}[\omega, \alpha]$. Notice that (trivially) a Reed-Solomon code is equivalent to every generalized Reed-Solomon code with the same evaluation points, i.e. $$\begin{equation}\label{Equiv}\tag{Equiv}RS_{n,k}[\omega] \cong GRS_{n,k}[\omega, \alpha] \quad \forall \alpha \in (\mathbb{F}^\times)^n.\end{equation}$$So the GRS codes are just a more redundant parameterization of the RS codes – nothing new is gained! Indeed, “generalized Reed-Solomon code” is a misleading name. Yet the GRS codes are more convenient when it comes to constructing equivalences: in order to demonstrate $RS_{n,k}[\omega] \cong RS_{n,k}[\omega’]$, it suffices to find $\alpha, \alpha’$ such that $GRS_{n,k}[\omega, \alpha] \cong GRS_{n,k}[\omega, \alpha’]$, and this is often easier.
For example, it turns out to be straight-forward to show the following (proof below) $$\begin{equation}\tag{Invert}\label{Invert}\forall \omega \in (\mathbb{F}^\times)^n \ \ \forall \alpha \in (\mathbb{F}^\times)^n \ \ \exists \beta \in ( \mathbb{F}^\times)^n \ \ : \ \ GRS_{n, k}[\omega, \alpha] = GRS_{n,k}[\omega^{-1}, \beta].\end{equation}$$ Indeed, $\beta_i = \alpha_i \omega_i^{-k}$ works. Setting $\alpha_i = 1 \ \forall i$ and invoking \eqref{Equiv} twice, this allows us to conclude that $$ RS[\omega] \cong GRS[\omega, \alpha] = GRS[\omega^{-1}, \beta] \cong RS[\omega^{-1}].$$This is a pretty neat result!
Following is a proof of \eqref{Invert}. While very simple, it seems to be peculiarly “linguistic” as it involves the re-ordering of some coefficients. We’ll explore this next.
(For more on the generalized Reed-Solomon codes and these equivalences, see these lecture notes).
Reed-Solomon codes as algebraic geometry codes
We’ve demonstrated that, if $\omega$ and $\omega’$ can be related by a composition of entry-wise affine transformations and inversions, then $RS_{n,k}[\omega] \cong RS_{n,k}[\omega’]$. Being able to build code equivalences from two apparently distinct sorts of transformations of $\mathbb{F}$ invites us to look for a more general context in which they are two instances of the same thing. A hint as to what that might be (if another was needed) is contained in the above proof of \eqref{Invert}: in what context does reversing the order of the coefficients of a polynomial become meaningful? This transformation would be more naturally described as interchanging the indeterminates of bivariate polynomials of homogeneous degree $k-1$. Indeed, the needed generalization uses the projective line $\text{P}^1(\mathbb{F})$ in place of $\mathbb{F}$ as the source of the evaluation points and uses “appropriate” functions on $\text{P}^1(\mathbb{F})$ in place of $\mathbb{F}[X]^{< k}$. The natural notion of functions on $\text{P}^1(\mathbb{F})$ are the “rational functions”: ratios of homogeneous bivariate polynomials where the numerator and denominator have the same degree. In this new context, the polynomials of degree $< k$ become those rational functions that only have poles at the point at infinity $(1:0)$, and then only of order $< k$. Importantly, these functions form a vector space, and the evaluation of any such function at an affine point $(\omega_i:1)$ is (since any pole could only be at infinity) an element of the field $\mathbb{F}$.
The first sort of equivalence of RS codes constructed above resulted from an affine transformation of $\mathbb{F}$. Just as invertible affine transformations transform the 1-dimensional affine space $\mathbb{F}$, homographies (i.e. isomorphisms of projective space) transform the projective line $\text{P}^1(\mathbb{F})$. A homography of the projective line has the form $$ (X:Y) \mapsto (aX + bY: cX + dY) \quad \forall (X:Y) \in \text{P}^1(\mathbb{F}),$$ for some invertible 2×2 matrix $\begin{pmatrix}a & b\\ c & d\end{pmatrix}$. Let’s consider some special cases. Setting $c=0, d=1$, this is (an extension of) an invertible affine transformation of $\mathbb{F}$. On the other hand, setting $a=d=0$, $b=c=1$, we have an extension of the map that inverts non-zero field elements (and induces an interchanging of the indeterminates of bivariate homogeneous polynomials!). So the homographies are sufficiently general to include the two sorts of transformations $\mathbb{F}$ used above to construct our equivalences of RS codes.
Thus we might define a “projective RS code” by beginning with a sequence of $n$ distinct points $P_i \in \text{P}^1(\mathbb{F})$ and a constraint on the maximum order of poles at every point on $\text{P}^1(\mathbb{F})$ (and such that no poles are permitted at any $P_i$). Call this constraint $D$ and write $L(D)$ for the linear space of all rational functions that satisfy the constraint $D$. Since no poles are permitted at the $P_i$, the evaluation map $\epsilon : L(D) \to \mathbb{F}^n$ is well-defined linear map. Indeed, given a further technical assumption on the constraint, $\epsilon$ is injective, and we’ve constructed an $(n,k)$ code where $k=\text{dim}(L(D))$. Clearly it includes the familiar RS codes, and indeed it can be shown (see e.g. Walker Theorem 6.4 & Exercise 6.6) that all these codes are MDS codes. The natural generalization of the code equivalences constructed above are constructed from homographies of $\text{P}^1(\mathbb{F})$. The homographies transform the evaluation points as well as the functions being evaluated (along with their constraint). The advantage of this viewpoint is that now there is nothing to prove: the linear code is defined using structures in projective space, and since homographies are the structure preserving maps of projective space, it is vacuously true that homographies induce equivalences of codes.
Instead of defining such codes, we go just one step further, and consider an arbitrary non-singular projective plane curve $\mathcal{C} \subset \text{P}^2(\mathbb{F})$ in place of the projective line. There are $n$ distinct evaluation points $P_i \in \mathcal{C}$, and the “constraint” on the order of the poles takes the form of a divisor $D$ on $\mathcal{C}$ whose support does not contain the $P_i$. The space of functions $L(D)$ are the rational functions on the curve associated to the divisor $D$, i.e. is the Riemann-Roch space. The dimension $k$ of the resulting algebraic geometry code $AG[\mathcal{C}, (P_1, \dots P_n), D]$ is determined by the degree of the divisor and the genus of $\mathcal{C}$.
Further reading
These lecture notes are an excellent elementary introduction to equivalences of GRS codes. See Walker’s “Codes & Curves” for a speedy introduction to algebraic geometry codes, and read The automorphism groups of Reed-Solomon codes (Dür, 1987) for a description of the automorphism group of Reed-Solomon codes in terms of fractional linear transformations (i.e. homographies of the projective line).
(The following thought experiment was suggested to me by my colleague Ryan Cao; mistakes and invective are my own).
FRI is often described as a “low degree test”, which suggests that the verifier should reject with high probability if the degree is high. This is not the case, as the simple example below demonstrates. Indeed it is the polynomials of highest degree that have the highest chance of being erroneously accepted by the verifier. (What is true is that the FRI verifier rejects with high probability if the evaluations are far from the code: FRI is a proof of proximity).
Let $\mathbb{F}$ be a field, $\Omega \subset \mathbb{F}$ with $n = |\Omega|$, and write $$ \epsilon_\Omega : \mathbb{F}[x]^{<n} \to \mathbb{F}^\Omega, \qquad f \mapsto (f(\omega))_{\omega \in \Omega} $$ for the evaluation map. For any $k \leq n$, let $\text{RS}[\Omega, k] := \epsilon_\Omega (\mathbb{F}[x]^{< k})$ be the Reed-Solomon code of evaluations of polynomials of degree strictly less than $k$ on $\Omega$.
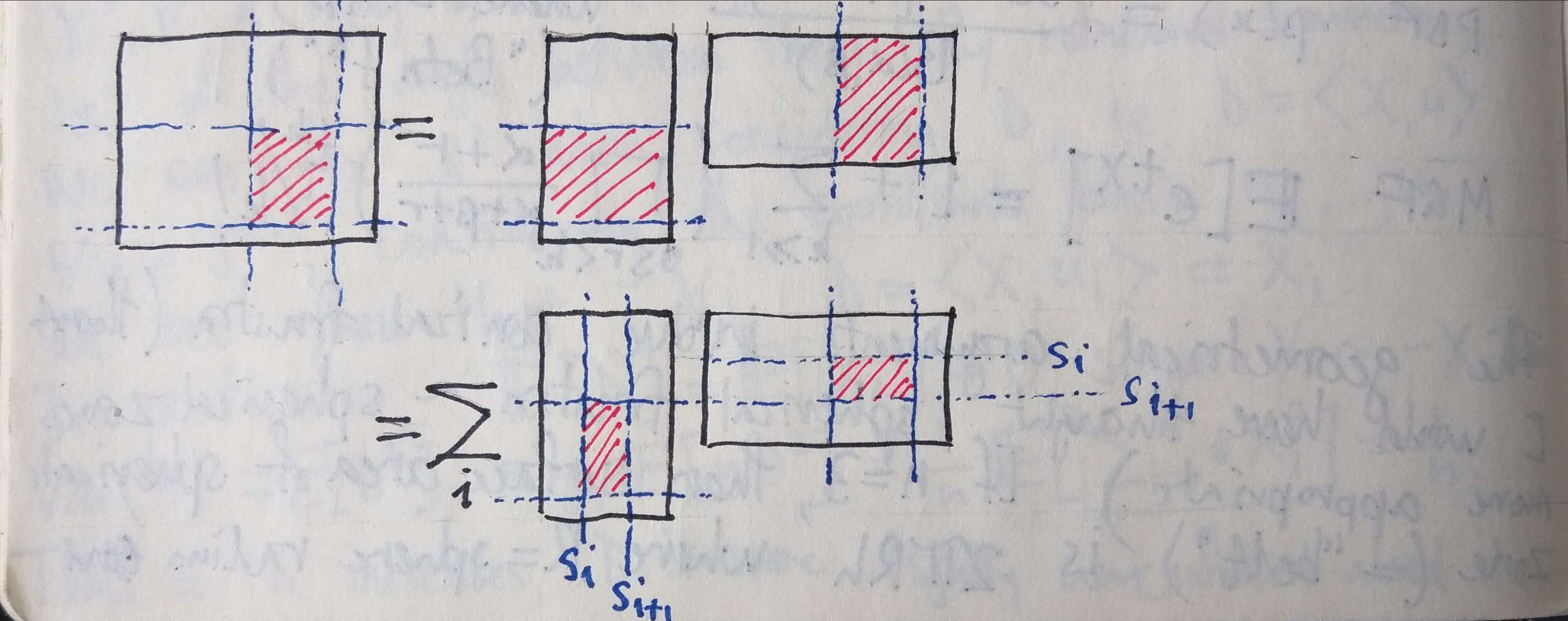
Henceforth we assume that $\Omega$ is a subgroup of the multiplicative group $\mathbb{F}^\times$ and that $n = |\Omega|$ is a power of two. The degree bound $k=2^d$ will also be a power of two. For $\alpha \in \mathbb{F}$, let $\Phi_\alpha : \mathbb{F}[x] \to \mathbb{F}[x]$ be the FRI folding operation (in the coefficient domain) and write $\Psi_\alpha = \epsilon_\Omega \circ \Phi_\alpha \circ \epsilon_\Omega^{-1}$ for the corresponding operation in the evaluation domain. Then it’s not hard to check that for any $v \in \mathbb{F}^\Omega$ and $\alpha \in \mathbb{F}$, we have $$\begin{equation}\textstyle \tag{Fold}\label{Fold} (\Psi_\alpha(v))_{\omega^2} = \frac{1}{2} (1 + \frac{\alpha}{\omega}) v_{\omega} + \frac{1}{2} (1 – \frac{\alpha}{\omega}) v_{-\omega} \quad \forall \omega \in \Omega.\end{equation}$$
FRI operates by iterated folding, using challenges provided by the verifier. The claim of the proximity of $v^{(0)} := v \in \mathbb{F}^\Omega$ to the code $\text{RS}[\Omega, 2^d]$ is reduced to the claim of the proximity of $v^{(1)} := \Psi_\alpha v^{(0)}$ to the code $\text{RS}[\Omega^2, 2^{d-1}]$ for some $\alpha \in \mathbb{F}$. This process is repeated until the claim is that $v^{(d)}$ is close to the code $\text{RS}[\Omega^{2^d}, 1]$, at which point the verifier queries $t$ entries from $v^{(d)}$ and checks if they all agree: if they do, it concludes that $v^{(d)}$ is (w.h.p.) close to its code, and hence that the original vector $v^{(0)}$ is (w.h.p.) close to the original code. Proving that FRI is indeed a good test of proximity is complicated. It is easy to show, however, that FRI is not (indeed never intended being) a reliable means of detecting polynomials of high degree, and that is what we’ll do here.
For any $\omega \in \Omega$, let $L_{\omega, \Omega}$ denote the Lagrange interpolation polynomial, i.e. $$ L_{\omega, \Omega} = \prod_{\substack{\omega’ \in \Omega \ \omega’ \neq \omega}} \frac{x – \omega’}{\omega – \omega’} \in \mathbb{F}[x].$$ Then $\text{deg} L = n – 1$, i.e. it has has maximal degree (given the size of the evaluation domain $\Omega$). Its evaluations, however, are “one-hot” at $\omega$ $$ v_{\omega, \Omega} := \epsilon_\Omega (L_{\omega, \Omega}) = (0, \dots, 0, 1, 0, \dots, 0) $$ and in this sense are maximally close to the code, while not being in the code (having Hamming distance $1$ from the zero codeword). It’s easy to see from \eqref{Fold} that $$ \Psi_\alpha(v_{\omega, \Omega}) = \frac{1}{2} (1 + \frac{\alpha}{\omega}) v_{\omega^2, \Omega^2} $$ i.e. that except with negligible probability (when $\alpha=-\omega$), the folding will also have Hamming distance 1 from its code $\text{RS}[\Omega^2, 2^{d-1}]$. Note, however, that the relative Hamming distance has doubled, since the size of the evaluation domain has halved.
So let’s set $v^{(0)} := v_{\omega, \Omega}$. Then after $d$ rounds of folding, $v^{(d)}$ is (except with negligible probability) non-zero in exactly one place, and its relative distance from the code $\text{RS}[\Omega^{2^d}, 1]$ (which consists of constant vectors) is $2^d / 2^n$ i.e. the rate $\rho$ of the original code. The verifier thus accepts with probability $(1 – \rho)^t$. Given that $\rho$ is typically close to zero (e.g. $2^{22-64}$) and $t$ is always small, this probability is close to $1$. For this reason, it is misleading (if commonplace) to describe FRI as a “low-degree test”: the polynomials $L_{\omega, \Omega}$, which have maximal degree are routinely accepted by the FRI verifier. Why? Because the evaluations of these polynomials are close (“proximal”) to the code. FRI is a proof of proximity, after all.
A polynomial with coefficients in a field and of degree $< n$ is determined by its evaluations at any $n$ distinct points. A common way to see this is via Lagrange interpolation. But what happens in the more general case where the coefficients come from a commutative ring $R$ with $1$? It’s easy to see that the statement fails. Consider e.g. $R = \mathbb{Z}/ 8\mathbb{Z}$, and let $f(X) = 4X + 4X^2$. Then $f$ vanishes everywhere on R (easy to check), despite having degree two. In particular, there are multiple polynomials of degree $< 3$ (viz. $f$ and the zero polynomial) that vanish at three distinct points e.g. $1, 2, 3$.
The circumstances under which a polynomial over a commutative ring is determined by its evaluations can be determined by considering the Vandermonde matrix. Recall that, given points $c_1, \dots, c_n \in R$, the Vandermonde matrix $V$ is the $n$ x $n$ matrix consisting of powers of the $c_i$. The matrix-vector product of $V$ and the vector of the coefficients of a polynomial $f$ then gives the vector of evaluations $f(c_i)$ of $f$ at the points $c_i$. Interpolation goes the other way, i.e. from evaluations to coefficients. So we’d like to be able to invert the Vandermonde matrix.
As it happens, a square matrix over a commutative ring $R$ with $1$ is invertible if and only if its determinant is invertible in $R$ (the construction of the inverse matrix in terms of the adjugate demonstrates this). The determinant of the Vandermonde can be shown (using only column operations and properties of the determinant) to be the product of the differences $c_i – c_j$ for $i \ne j$. Thus we see that a polynomial $f \in R[X]$ of degree $< n$ is determined by its evaluations at $n$ distinct points if the differences of these evaluation points are invertible in $R$.
In fact, we can do much better: the differences don’t need to have inverses in $R$, they just need to be invertible in a larger ring: it in fact suffices that the differences are not zero divisors in $R$. For suppose that this is the case. Let $S$ be the multiplicative closure of the set of pairwise differences. Then $S$ contains no zero divisors, and so $R$ can be considered as a subring of its localization $S^{-1}R$ at the subset $S$. Importantly, the pairwise differences have inverses in $S^{-1}R$. Hence, by the above argument, any polynomial of degree $< n$ with coefficients in $S^{-1}R$ is determined by its evaluations at our points, and this of course continues to hold when the coefficients (and evaluations) lie in the subring $R$.
To return to the problematic example above: for any three distinct points in $R = \mathbb{Z}/ 8\mathbb{Z}$, either at least two of them are odd, or at least two of them are even, and in either case there will be a pair of distinct points whose difference is even and hence either zero or a zero divisor.
The Vandermonde matrix computes evaluations of polynomials from their coefficients via a matrix-vector product. The Vandermonde matrices are nested, i.e. each Vandermonde matrix is the principal submatrix of any larger Vandermonde matrix that uses (an extension of) the same sequence of evaluation points. For example, here is the (square) Vandermonde matrix for the evaluation points $0, 1, 2, 3$; the Vandermonde matrix for $0, 1, 2$ is the $3$ x $3$ principal (i.e. top-left) submatrix:
If the inverse Vandermonde matrix exists, then the inverse computation (from evaluations to coefficients, i.e. polynomial interpolation), can also be performed as a matrix-vector product (for the inverse of the Vandermonde matrix to exist, it must be square and the evaluation points must be distinct). Unfortunately, the inverse Vandermonde matrices are no longer “nested” in the above sense. For example, here are the inverse Vandermonde matrices for evaluation points $0, 1, 2$ and $0, 1, 2, 3$.
Who cares? Well, it would be nice if they were nested since then one could pre-compute a sufficiently large inverse Vandermonde matrix, and be able to interpolate any polynomial that came along. But it just isn’t so! However, for the particular case where the evaluation points are the non-negative integers (and indeed in many more general cases), the neatness can be restored using a certain triangular decomposition of the Vandermonde matrix and its inverse.
Let’s write $V_n$ for the Vandermonde matrix defined by the evaluation points $0, 1, .., n$. Then $V_n$ can be expressed as a product of a lower-triangular, diagonal and upper-triangular matrices $L_n$, $D_n$, and $U_n$ i.e. $V_n = L_n D_n U_n$. Thus $V_n^{-1} = U_n^{-1} D_n^{-1} L_n^{-1}$. It turns out that all of these factors form nested families in the sense above. For example, $U_n$ is the principal $n$ x $n$ submatrix of any $U_{n+k}$, while $L_n^{-1}$ is the principal $n$ x $n$ submatrix of $L_{n+k}^{-1}$, and so on. Thus if we pre-compute $L_n^{-1}, D_n^{-1}, U_n^{-1}$ then we’ll be able to interpolate any polynomial of degree at most $n$ (by selecting the appropriate principal submatrix of each factor, and then performing three matrix-vector multiplications).
Furthermore, the entries of $L^{-1}, D^{-1}, U^{-1}$ (also of $L$, $D$, $U$) are given by pleasing and useful recursive formulae, and these can be used to increase the size of your precomputed matrices as required. For instance, $(L^{-1})_{i,j} = (-1)^{i-j} \binom{i}{j}$ and the identity $$\binom{i}{j} = \binom{i-1}{j-1} + \binom{i-1}{j}$$ is easily adapted to a recurrence on the $(L^{-1})_{i,j}$ that allows us to extend $L^{-1}$ as needed. The diagonal entries of $D^{-1}$ are given by $(D^{-1})_{i,i} = \frac{1}{i!}$ (recurrence obvious) while the entries of $U^{-1}$ are given by the (signed) Sterling numbers of the first kind via $(U^{-1})_{i,j} = s(j,i)$. These quantities satisfy the recurrence $$s(j, i) = s(j-1, i-1) – (j-1) s(j-1,i)$$ with boundary conditions $s(0,0) = 1$ and $s(k, 0) = s(0, k) = 0$ for all $k > 0$.
These formulae were first derived in Vandermonde matrices on integer nodes (Eisinberg, Franzé, Pugliese; 1998). Another useful (and freely available) reference is Symmetric functions and the Vandermonde matrix (Oruç & Akmaz; 2004) which deals with the case of $q$-integer nodes (take $q=0$ in their Theorem 4.1 to obtain the formulae above).
We recount here an elementary proof of associativity for the group law on a non-singular elliptic curve. The principal ingredient is the Cayley-Bacharach theorem, which has a neat combinatorial proof using only a corollary of Bézout’s theorem (see “further reading” below).
Theorem (Cayley-Bacharach): Let $D, D’$ be two cubic curves intersecting in nine distinct points. If $D^″$ is a cubic curve through eight of the nine points, then it has the form $D^″ = aD + a’D’$ for some $(a:a’) \in \mathbb{P}_1(k)$ and in particular goes through the ninth point.
Note that “curve” in this context just means zero set in the projective plane of some homogeneous (not necessarily irreducible) polynomial. In particular, the union of three distinct lines in the projective plane is a cubic curve, by this definition, being the zero set of a product of three linear polynomials.
Theorem: Let $E$ be a non-singular elliptic curve with base point (=identity) $O \in E$ and addition defined (as usual) via $P + Q := O \circ (P \circ Q)$ where $P \circ Q$ denotes the third point of intersection of $E$ with the line through $P$ and $Q$, for all $P, Q \in E$. Then for all $P, Q, R \in E$ distinct we have $$ P + (Q + R) = (P + Q) + R.$$
Proof: First notice that since $$ P + (Q + R) = O \circ (P \circ (Q + R)) $$ and $$ (P + Q) + R = O \circ ((P + Q) \circ R), $$ the identity $$ O \circ (O \circ X) = X \quad \forall X \in E$$ implies that it is sufficient to show that $$ P \circ (Q + R) = (P + Q) \circ R.$$
Consider the following diagram. A red line and a blue line intersect the curve $E$ inside the dotted circle. Our goal is to show that these two intersections occur at the same point of $E$ (as indeed they appear to, in the diagram).
Let $l, l’, l^″$ be an enumeration of the red lines, $m, m’, m^″$ an enumeration of the blue lines as follows:
Define cubics $L = l l’ l^″$, $M = m m’ m^″$ (these are the red and blue triangles in the first diagram). Then $E$ and $L$ meet at exactly nine points.
We assume that the eight points $O, P, Q, R, P \circ Q, Q \circ R, P + Q, Q + R$ (in black on both diagrams) are distinct from one another and also from $P \circ (Q + R)$ and $(P + Q) \circ R$ (i.e. the points we are trying to show are equal).
Then $E$ and $L$ have nine points in common (the black points and $(P + Q) \circ R$), and moreover cannot share more than these, since otherwise Bézout’s Theorem (applied to $E$ and each component $l, l’, l^″$ of $L$) would imply that one of these components $l, l’, l^″$ belonged to $E$, thereby contradicting the assumed non-singularity of $E$ (since this implies irreducibility, see note below).
Similarly, $E$ and $M$ share precisely nine points, viz. the black points and $P \circ (Q + R)$. Now $M$ contains eight points (the black points) that are shared by $E$ and $L$, and hence contains also the ninth, by the Cayley-Bacharach Theorem, i.e. $(P + Q) \circ R \in M$.
So $E$ and $M$ share precisely nine points. On the other hand, we’ve shown that they share ten points: the eight black points, $P \circ (Q + R)$, and $(P + Q) \circ R$. Hence, in view of the point distinctness assumptions, the last two points must be equal.
Notes
Non-singular curves are irreducible since reducible curves are necessarily singular (since components must intersect by Bézout’s Theorem, and these intersection points are necessarily singularities).
Questions
The distinctness assumptions are sufficient in view of Zariski closure?
Further reading
Husemöller’s book “Elliptic Curves” (page 51, 2nd edition) proves this, as well as the Cayley-Bacharach theorem itself, along with the corollary of Bézout’s theorem needed for it.
Terence Tao’s blog covers the same material as above (and does a much better job of it).
The following is intended as an introduction to finite fields for those with already some familiarity with algebraic constructions. It is based on a talk given at our local seminar.
A finite field is simply a field with a finite number of elements. An example of a finite field that should already be familiar is $\mathbb{Z} / p \mathbb{Z}$, the integers modulo a prime $p$, which in the context of field theory is more commonly denoted $\mathbb{F}_p$. But what other finite fields exist? In this post, we’ll construct a finite field $\mathbb{F}_{p^n} = GF(p^n)$ of size $p^n$ for any prime $p$ and positive integer $n$, and additionally prove that, up to isomorphism, these are all the finite fields.
(Note that another common notation for $\mathbb{F}_{p^n}$ is $GF(p^n)$ – the “GF” stands for “Galois field”).
$\mathbb{F}_p$ is a field
Firstly, let’s take a moment to show why $\mathbb{F}_p$ is a field. It is clearly is a commutative ring with 1, so it remains to see why every non-zero element $a$ has an inverse. We need to find an element $x$ such that $ax \equiv 1 \mod p$. The Extended Euclidean Algorithm provides a way to find such a $x$. The algorithm takes two positive integers $a, b$ and returns integer coefficients that linearly combine $a$ and $b$ to yield their GCD, i.e. such that $ax + by = \gcd(a, b)$. Take $b=p$. Since $p$ is prime and $a$ is not zero, $\gcd(a, p) = 1$. The Euclidean algorithm therefore yields $x$ and $y$ such that $ax + py = 1$, which means $ax \equiv 1 \mod p$. Hence, $x$ is the multiplicative inverse of $a$.
This same argument will be recycled below in our construction of extension fields.
The characteristic of a field
The characteristic of a field $K$ is the smallest positive integer $p$ such that $p \cdot 1 := 1 + \cdots + 1$ ($p$ times) equals $0$ in $K$. In other words, it is the order of the additive group generated by the element $1$.
If $K$ is finite, then it is clear that such a $p$ must exist. Moreover, $p$ must be prime. For supposing that $p$ factorized, as say $p=rs$ with $1 < r, s < p$, it would follow that \begin{equation}\label{ZD}\tag{ZD}(r \cdot 1) (s \cdot 1) = 0,\end{equation} while at the same time, by minimality of the characteristic, we’d have that neither of the multiplicands $r\cdot 1$, $s \cdot 1$ were themselves zero. To arrive at a contradiction, either note that you’ve constructed zero divisors in a field, or instead use that fact that $r \cdot 1$ (being non-zero) has an inverse, multiply both sides of \eqref{ZD} by that inverse and note that this would force $s \cdot 1 = 0$, a contradiction.
(A similar argument shows that $\mathbb{Z} / m\mathbb{Z}$ is not a field if $m$ is not prime).
If no positive integer $p$ exists such that $p \cdot 1 = 0$, the characteristic is defined to be zero (this is the case for $\mathbb{Q}, \mathbb{R}, \mathbb{C}$, for example).
The prime subfield
A subfield of a field is simply a subset which is itself a field (with the same $1$ and $0$). The prime subfield of a field $K$ is the subfield generated by $1$ and is the smallest subfield contained in $K$. If the characteristic of $K$ is a prime number $p$, then the prime subfield is (a copy of) the field $\mathbb{F}_p$. If the characteristic of $K$ is zero, then the prime subfield is isomorphic to the field of rational numbers $\mathbb{Q}$.
Of course, the prime subfield could be the entire field!
Any finite field has size a prime power, and that prime is its characteristic
Let $K$ be a finite field of characteristic $p$, and identify $\mathbb{F}_p$ with the prime subfield of $K$. Now let’s forget some of the structure of $K$ and just consider $K$ as a vector space over the field $\mathbb{F}_p$. The vector space axioms are indeed satisfied, since elements of $K$ can be added together, and multiplied by scalars (i.e. elements of $\mathbb{F}_p$) in a way that is distributive and associative – all of this just follows from the field axioms.
Now let $n \geq 1 $ be the dimension of $K$ as a vector space over $\mathbb{F}_p$. If you chose a basis for $K$, it would have length $n$, and every element of $K$ would have a unique expression as a linear combination of the basis with coefficients in $\mathbb{F}_p$. Moreover, every such expression would be an element of $K$. There are $p^n$ such expressions, so $| K | = p^n$.
Example: there is precisely one field with four elements
While we will indeed construct $\mathbb{F}_{p^n}$ for every prime $p$ and $n >0$, let’s first do the simplest possible example beyond the more familiar fields $\mathbb{F}_p$: let’s “manually” construct a field $\mathbb{F}_4$ with four elements. Indeed, we’ll see that there is only one such field, up to isomorphism.
Firstly, note that $\mathbb{F}_4$ has characteristic 2 (by the preceding section), and hence has $\mathbb{F}_2$ as its prime subfield. So there are only two “new” field elements. Call them $A, B$, so that $\mathbb{F}_4 = \{ 0, 1, A, B \}$. Note that the four elements must all be pairwise non-equal, or the field is too small. Now, try to fill in the multiplication table for this new field, using the fact that the non-zero elements of a field (in our case: $1, A, B$) must form a group under multiplication. This implies that each element can appear at most once in each row and column. You’ll see that there is only one way to do this!
Similarly, try filling in the addition table, this time using the fact that the field is a group under addition, as well as $A + A = A \cdot (1 + 1) = A \cdot 0 = 0$ (similarly for $B$). There is only one possible addition table!
Below, we’ll construct this same finite field (and many others) but in a more sophisticated manner.
Polynomial prerequisites
Polynomial division
Given two polynomials $f, g \in K[x]$, $f \ne 0$, we can perform polynomial division to write $g(x) = q(x)f(x) + r(x)$ for some unique $q, r \in K[x]$ such that $ \text{deg}(r) < \text{deg}(f)$. Call $q$ the quotient and $r$ the remainder. This is analogous to the division algorithm for integers.
Roots correspond to linear factors
A polynomial $f(x)$ has a root $\lambda$ if and only if it is divisible by the linear polynomial $(x – \lambda)$. This can be seen using polynomial division: for if $f(x)$ is divided by $(x – \lambda)$, then the remainder is $f(\lambda)$. Hence, $f(\lambda) = 0$ if and only if the remainder is zero, which means $f(x)$ is divisible by $(x – \lambda)$.
Aside: a finite field is never algebraically closed
While this subsection has no relevance to the construction below, it is too nice to omit! Recall that a field $K$ is said to be algebraically closed if every non-constant polynomial $f(x) \in K[x]$ has a root in $K$. For example, $\mathbb{C}$ is algebraically closed, while $\mathbb{R}$ is not. Now if $K$ is a finite field, form the polynomial $$f(x) = (\prod_{\lambda \in K} (x – \lambda) ) + 1 $$ and notice that $f(\lambda) \ne 0$ for any $\lambda \in K$. Thus $K$ can not be algebraically closed.
Irreducible polynomials
An irreducible polynomial over a field $K$ is a non-constant polynomial that cannot be factored into the product of two non-constant polynomials over $\mathbb{F}$. Irreducibles of degree three or lower are easy to find: any factorization must involve a linear factor, and these can be detected by evaluating the polynomial (as discussed above).
Exercise 1: Verify that, over $\mathbb{F}_2$, the polynomial $x^2 + x + 1$ is the unique quadratic irreducible.
Exercise 2: (Again over $\mathbb{F}_2$) show that $x^3 + x + 1$ and $x^3 + x^2 + 1$ are the unique cubic irreducibles.
A stepping stone: constructing new fields from old
Let $K$ be any field (not necessarily finite) and let $f \in K[x]$ an irreducible polynomial of degree $n$. Write $ K_{(f)} = K[x] / f K[x]$ for the quotient of the ring $K[x]$ by the ideal generated by $f$. Then $K_{(f)}$ is itself a ring with $1$. Let $\pi : K[x] \to K_{(f)}$ be the surjection of rings that comes from the quotient construction, i.e. that maps any polynomial $g$ to its coset $g + f K[x]$.
Just as the elements of $\mathbb{Z} / p \mathbb{Z}$ are enumerated by remainders after integer division by $p$, the elements $g + f K[x]$ of $K_{(f)}$ can be enumerated by remainders $r(x)$ of polynomial division of $g(x)$ by $f(x)$: if $g=qf + r$, then $\pi(g) = \pi(r)$. If $K$ is indeed finite, this immediately tell us that $|K_{(f)}| = |K|^n$, since there are $|K|$ possibilities for each of the $n = \text{deg} (f)$ coefficients of $r(x)$.
There is moreover an extended Euclidean algorithm for polynomials, and (analogous to our argument for $\mathbb{Z} / p \mathbb{Z}$) this can be used to demonstrate that every non-zero element of $K_{(f)}$ has an inverse. For if $a$ is such an element, than there exists a $g \in K[x]$ with $\pi(g) = a$, and we have that $g$ is not divisible by $f$, since $a \ne 0$. Thus, the greatest common divisor of $f$ and $g$ (which is defined to be the monic polynomial of maximal degree dividing both $f$ and $g$), in view of the irreducibility of $f$, must be $1$. The extended Euclidean algorithm therefore yields polynomials $s, t \in K[x]$ such that $sf + tg = 1$, and applying $\pi$ to both sides of this equation shows that $\pi(t) = \pi(g)^{-1}$, i.e. $\pi(t)$ is the inverse of $a = \pi(g)$.
We’ve thus shown that $K_{(f)}$ is a field. Indeed, it has $K$ as a subfield, and so $K \subset K_{(f)}$ is a field extension. It is, in fact, quite a special field extension – the polynomial $f$, which was irreducible over $K$, has a root $K_{(f)}$, namely $\pi(x)$. To see this, first note that $\pi$ is a $K$-linear map. Then: $$ f (\pi (x)) = \sum_i f_i (\pi(x))^i = \sum_i f_i \pi (x^i) = \pi \left(\sum_i f_i x^i \right) = \pi (f (x)) = 0.$$
In summary, given a field $K$ and an irreducible $f \in K[x]$ of degree $n$, we’ve constructed an extension field of $K$ in which $f$ has a root!
Note that we’d have achieved our goal of constructing a field with $p^n$ elements if we knew that there was an irreducible polynomial of degree $n$ over $\mathbb{F}_p$. But we don’t know this at this stage. Nonetheless, the above construction is the crucial ingredient, as we’ll see below.
Exercise 3: Verify that the complex numbers $\mathbb{C}$ can be constructed from the real numbers $\mathbb{R}$ in this way, using the irreducible quadratic $f(x) = x^2 + 1 \in \mathbb{R}[x]$. In particular, you should recover the familiar formulae for the real and complex parts of the multiplication of two complex numbers from multiplication in $K_{(f)}$. (For a worked solution, see here).
Exercise 4: Carry out the above construction for $K = \mathbb{F}_2$ and the irreducible $f(x) = x^2 + x + 1 \in K[x]$, and check that you obtain the field with four elements (which we constructed earlier in manual fashion).
Exercise 5: (continuing the example of the previous exercise) Show that both roots of $f$ are obtained ($\pi(x)$ is one of them, which is the other?). Though we won’t use (or show) this here, it turns out that this is always true if $K$ is finite, then $f$ will factor completely into linear factors over the extension field $K_{(f)}$. You can cycle through the roots by applying the Frobenius automorphism.
Existence of a splitting field
Suppose $K$ is a field (not necessarily finite) and $h \in K[x]$ a non-constant polynomial. A splitting field for $h$ is a field $L$ extending $K$ (so $K \subset L$) over which $h$ splits as a product of linear factors, and that is minimal with the property, i.e. if $L’$ with $K \subset L’ \subset L$ is another such field, then $L’ = L$.
We show here that splitting fields exist (a special case of which will be the last ingredient in our construction of the finite fields).
We proceed iteratively. $h$ has a unique expression as a product of irreducibles over $K$. If this expression consists only of linear factors, then stop. If not, choose a non-linear (i.e. degree > 1) irreducible factor $f$, and construct the field $K_{(f)}$ as above. Considering $h \in K_{(f)}[x]$, we see that $h$ has at least one more linear factor than before. Repeat this process, each time replacing $K$ by $K_{(f)}$ where $f$ is one of the remaining non-linear irreducible factors of $h$. Since polynomials have finite degree, this process which terminate with a field $\hat L$ over which $h$ factors linearly. Now take the smallest subfield $L \subset \hat L$ over which $h$ factors linearly (such a field is uniquely determined, since the intersection of any two subfields with this property will again be a subfield with this property). Then we have constructed a splitting field for $h$.
Construction of a field with $p^n$ elements
Finally! Using the construction of the previous section, let $L$ be a splitting field of $h(x) = x^{p^n} – x \in \mathbb{F}_p [x]$. So $\mathbb{F}_{p^n} \subset L$. Now let $L’ = \{ \lambda \in L \,|\, h(\lambda) = 0 \}$. It remains to show that $L’$ is a field and $|L’| = p^n$.
To see that $L’$ is a field, first note that $0, 1 \in L$ are both roots of $h$, so $0, 1 \in L’$. Now simply show that $L’$ is closed under addition, multiplication, and inversion. Only addition is not immediate: for this, you need to use that the binomial coefficients $\binom{p^n}{k}$ vanish in characteristic $p$ whenever $0 < k < p^n$ (which follows from the definition of the binomial coefficient in terms of factorials, c.f. here). Thus $L’$ is a field.
Finally, note that $|L’|$ is equal to the number of distinct roots of $h$. The polynomial $h$ has degree $p^n$, but perhaps there are repeated roots? There are not. If a root $\lambda$ was repeated, then $(x – \lambda)^2$ would divide $h$. But if this were the case, then $(x – \lambda)$ would divide its derivative $\frac{dh}{dx}$ (this follows immediately from the product rule for differentiation). But direct calculation shows that $\frac{dh}{dx} = -1$ (in characteristic $p$), and so $h$ can have no repeated roots. Hence $|L’| = p^n$, and we have constructed a field with $p^n$ elements!
Extension: these are all the finite fields
In the previous section, we constructed a splitting field $L’$ for the polynomial $h(x)$ and showed that it had $p^n$ elements. But could there be multiple, non-isomorphic fields of size $p^n$? There can not, as we see below. We need this uniqueness up to isomorphism in order to be able to sensibly speak of “the field $\mathbb{F}_{p^n}$ with $p^n$ elements”!
Suppose that $K$ is some other field with $|K| = p^n$, so $\mathbb{F}_{p} \subset K$. Then the set of all non-zero elements of $K$ is a multiplicative group of size $p^n – 1$. Thus for any non-zero $\lambda \in K$, we have that $\lambda^{p^n – 1} = 1$, or, put differently, that $\lambda^{p^n} – \lambda = 0$, i.e. $h(\lambda) = 0$! Note that this holds also for $\lambda = 0$, so we’ve shown that every element of $K$ is a root of $h$. Since $|K| = p^n = \text{deg}(h)$, it follows that $h$ factors linearly over $K$, and that $K$ is a minimal extension of $\mathbb{F}_p$ with this property since $h$ has no repeated factors (as seen in the previous section). Thus $K$ is a splitting field for $h$ as well, i.e. all fields of size $p^n$ are splitting fields for $h$.
Splitting fields are unique up to isomorphism in the sense detailed below. This statement is trivial if, as some authors do, you chose to consider only fields inside of a fixed algebraic closure of $\mathbb{F}_p$. If, like me, you would prefer not to do this, you might proceed as follows.
(This is an extremely useful fact with a straightforward proof. It follows from this, for instance, that any finite extension of a finite field is simple).
Let $\mathbb{K}$ be a finite field, so $|\mathbb{K}| = p^n$ for some prime $p$ and $n \geq 0$. Denote by $\mathbb{K}^\times$ the multiplicative group consisting of the non-zero elements of $\mathbb{K}$. We show that $\mathbb{K}^\times$ is cyclic, i.e., generated by a single element.
Let $d$ be the lowest common multiple (LCM) of the orders of all the elements $a \in \mathbb{K}^\times$. Then $d \mid |\mathbb{K}^\times| = p^n – 1$, and by Lagrange’s theorem, $a^d = a$ for all $a \in \mathbb{K}$, i.e. $$ (x – a) \mid x^{d + 1} – x \quad \forall a \in \mathbb{K}. $$ Hence, $p^n \leq d + 1$, since $x^{d+1} – x$ can have at most $d+1$ roots. Thus $$ p^n – 1 \leq d \leq p^n – 1 $$ i.e. $d = p^n – 1$.
It remains to show that there exists an element whose order is the LCM of the orders of all group elements. Indeed, this is generally true for abelian groups, as shown by the following.
Proposition: Let $G$ be an abelian group and let $a, b \in G$ be elements with finite orders $\alpha, \beta$ (respectively). Then there exists $c \in G$ of order $\text{LCM}(\alpha, \beta)$.
Proof: First, suppose $\alpha$ and $\beta$ are co-prime and set $c = ab$. Then if $c^i = 1$, then $a^i = b^{-i}$ and so $$ (b^{-1})^{i\alpha} = a^{i\alpha} = (a^\alpha)^i = 1, $$ so $\beta \mid i \alpha$ which implies $\beta \mid i$ by co-primality. Similarly, $\alpha \mid i$. So $\alpha\beta \mid i$ since $\alpha$ and $\beta$ are co-prime, so $c$ has order $\alpha\beta$.
Now consider the general case and write $$ \alpha = \prod_i p_i^{m_i}, \quad \beta = \prod_i p_i^{n_i} $$ where the $p_i$ are distinct primes. For each $i$, define $(M_i, N_i)$ by $$(M_i, N_i) = \begin{cases} (m_i, 0) & \text{if } m_i \geq n_i \\ (0, n_i) & \text{otherwise} \end{cases}$$ and let $$\alpha’ = \prod_i p_i^{M_i},\quad \beta’ = \prod_i p_i^{N_i}.$$ Then $\alpha’ \mid \alpha$ and $\beta’ \mid \beta$, while $\alpha’$ and $\beta’$ are co-prime and $\alpha’ \beta’ = \text{LCM}(\alpha, \beta)$. We have $$ \text{ord}(a^{\alpha / \alpha’}) = \alpha’ \quad \text{and} \quad \text{ord}\left( b^{\beta / \beta’} \right) = \beta’.$$ Thus by the coprime order case first considered, their product $ab$ has order $\alpha’ \beta’ = \text{LCM}(\alpha, \beta)$.
While there is famously no “royal road to geometry”, I believe that there is a royal road to understanding the wonderful logUp, a lookup argument from Starkware’s Shahar Papini and Polygon’s Ulrich Haböck. We’ll take this royal road here. This is significantly more direct than the approach taken in the two papers. The advantage of the exposition of the papers is that the thought processes that led to the final formulation are apparent (which is appreciated). The advantage of the exposition here is that it is formulated with the benefit of hindsight and ignores the historical development. Consequently (I hope!), you’ll get to the heart of the matter faster.
The setup for any lookup argument is a “table” $t$ of values that are permitted, and a “witness column” $w$ consisting of values to be checked. Both the table and witness column are multisets, typically represented as one-dimensional arrays of field elements, where repetition of an element in the array is used to represent multiplicity of that element in the multiset. The goal a lookup is to demonstrate (with high probability) that all of the witness values appear in the table, or equivalently, that considered as sets (i.e. ignoring multiplicities), the witness is a subset of the table, i.e. \begin{equation}\textstyle \tag{Subset}\label{Subset} \forall i \ \exists j \ :\ w_i = t_j .\end{equation} The table and witness are typically different lengths, but we’ll assume for simplicity that they are both powers of two, say $$ \textstyle w = (w_i)_{i=0, \dots, 2^M – 1} \qquad t = (t_j)_{j=0, \dots 2^N – 1}, $$ for some $M, N \geq 0$.
What’s wrong with the naive approach to lookups?
To see what’s truly wonderful about logUp, it’s crucial to see what’s wrong with a “naive” lookup argument. A typical lookup argument (not logUp) would show \eqref{Subset} by exhibiting, for each table entry $t_j$, a non-negative integer $m_j \geq 0$ and then showing (via random evaluation) that the following polynomial equality holds \begin{equation}\tag{Naive}\label{Naive} \textstyle \prod_{i=0}^{2^M – 1} (X – w_i) = \prod_{j=0}^{2^N – 1} (X – t_j)^{m_j}.\end{equation} To see why this is problematic, consider how the exponentiations on the right hand side will be computed in circuit using addition and multiplication gates. Before anything else, $X$ is replaced with a random field element $\alpha$ (in pursuit of Schwartz-Zippel). Then, for each $(\alpha-t_j)$, all of the powers \begin{equation} \textstyle (\alpha – t_j)^{2^0}, (\alpha – t_j)^{2^1}, (\alpha – t_j)^{2^2}, \dots, (\alpha – t_j)^{2^M – 1}\end{equation} need to be computed by repeated squaring. These powers are then combined to obtain $(\alpha – t_j)^{m_j}$: $$ \textstyle (\alpha – t_j)^{m_j} = \prod_{k=0}^{M – 1} \left( b_k^{(j)} (\alpha – t_j)^{2^k} + (1 – b_k^{(j)}) \right),$$ where $m_j = \sum_{k=0}^{M – 1}{b_k^{(j)} 2^k}$ is the binary decomposition of $m_j$ into bits $b_k^{(j)}$, for $j=0, \dots M-1$. And that’s the problem: not only do the multiplicities $m_j$ need to be provided to the circuit as inputs, but so do their binary decompositions! This is a factor of $M$ (=log of witness length) blow up in the number of circuit inputs, which is expensive.
What’s so great about logUp?
LogUp demonstrates that \eqref{Subset} by exhibiting, for each table entry $t_j$, a field element $m_j \in \mathbb F$ such that that the following “logUp identity” holds: \begin{equation}\tag{LogUp}\label{LogUp} \textstyle \sum_{i=0}^{2^M – 1} \frac{1}{X – w_i} = \sum_{j=0}^{2^N – 1} \frac{m_j}{X – t_j}. \end{equation} Setting aside for a moment the meaning of the inverse polynomial summands, we can see already why logUp is great. The multiplicities are not non-negative integers, but rather field elements, and using them in circuit involves just scalar multiplication! In particular, no binary decomposition of the multiplicities is required, resulting in significantly fewer inputs to the circuit (in contrast to the naive approach outlined above).
The logarithmic derivative
The logarithmic derivative of a function is just the derivative of its logarithm. If you apply this transformation to both sides of naive lookup equation \eqref{Naive}, you’ll see you get the logUp equation \eqref{LogUp}. To do this, you’ll need to work symbolically, treating polynomials as formal objects (not functions, see below). While this connection between the two equations is conceptually pleasing (and important for understanding where logUp came from), it is worth noting that proof of the soundness of the logUp approach doesn’t use the logarithmic derivative. See Lemma 5 (which relies on Lemma 4) of the 2022 logUp paper, or see below for an alternative proof.
The logUp identity is an equation in the field of fractions
Before attempting to show that the logUp identity is equivalent to the subset relation, let’s pause to think about where the logUp identity \eqref{LogUp} “lives”.
Recall that polynomials are formal arithmetic combinations of field elements and an indeterminate (so e.g. $X^2 \ne X$ in $\mathbb{F}_2[X]$, even though they coincide as functions $\mathbb{F}_2 \to \mathbb{F}_2$, because they are distinct formal sums; c.f. here). There is no danger in making this distinction. Any equality between two polynomials is also an equality between their corresponding polynomial functions (since evaluation at any point is a ring homomorphism).
The field of fractions $\mathbb{F}(X)$ is similarly a formal object, consisting of pairs of polynomials $(p, q)$, where $q \ne 0$, that are considered up to an equivalence that mimics that of fractions, i.e. $(p,q) \sim (p’, q’)$ if and only if $pq’ = p’q$. These pairs can be formally added and multiplied in the way that seems natural if one writes $p/q$ for $(p,q)$ (if unfamiliar, have a play and convince yourself that all is okay). With addition and multiplication so defined, $\mathbb{F}(X)$ becomes a field. Hence the name “field of fractions”.
The logUp identity \eqref{LogUp} is an equality in the field of fractions $\mathbb{F}(X)$.
How to show \eqref{LogUp}: Schwartz-Zippel for the field of fractions
Let $p(X), q(X)$ be the polynomials given by $$\frac{p(X)}{q(X)} = \left(\sum_{i=0}^{2^M – 1} \frac{1}{X – w_i} \right) \ -\ \left(\sum_{j=0}^{2^N – 1} \frac{m_j}{X – t_j} \right),$$ where $q(X)$ is the obvious product of all the denominators (i.e. with repetition). To show that the logUp identity \eqref{LogUp} holds, we need to show that $p(X) / q(X) = 0 / 1$ in $\mathbb{F}(X)$, i.e. that $p(X) = 0$ and $q(X) \ne 0$. Random evaluation (a.k.a. Schwartz-Zippel) can be used to show both of these simultaneously (w.h.p.). There are two small caveats: (i) if you’re unlucky and you hit a root of $q(X)$, you’ll need to resample, and (ii) strictly speaking, you need to take the inverse of the evaluation of $q(X)$ as an input to the circuit to show that that evaluation is indeed non-zero in circuit.
For randomly sampled $\alpha \in \mathbb{F}$, if $$ \alpha \ne w_i \ \ \forall i, \quad \wedge \quad \alpha \ne t_j \ \ \forall j, \quad \wedge \quad \sum_i \frac{1}{\alpha – w_i} = \sum_j \frac{m_j}{\alpha – t_j}$$ then (since evaluation at any $\alpha$ is a ring homomorphism) $$ p(\alpha) = 0 \quad \wedge \quad q(\alpha) \ne 0$$ from which it follows (w.h.p.) that $\frac{p(X)}{q(X)} = 0$, which implies \eqref{LogUp}.
In the above, we mentioned taking $q(\alpha)^{-1}$ as an input to the circuit, in order to demonstrate that $q(\alpha)$ is non-zero. If the field is large, then this check can be skipped with only a small soundness hit, since the the probability that $q(\alpha)$ is non-zero (given that $\alpha$ is randomly sampled) is bounded by $(2^M + 2^N) / |\mathbb{F}|$.
The logUp relation \eqref{LogUp} is equivalent to the subset relation \eqref{Subset}
As mentioned, this is shown in Lemma 5 and 4 of the 2022 paper. We show it here in a different way.
One direction of implication is trivial: if \eqref{Subset}, then \eqref{LogUp} clearly holds. Note that this is irrespective of the characteristic of the field (not so for the converse, as we’ll see).
We prove the converse statement (i.e. \eqref{LogUp} implies \eqref{Subset}) via the contrapositive, but for this we need the assumption $2^M < \text{char}(\mathbb F)$, i.e. that the witness length is bounded by the characteristic of the field. Suppose that \eqref{Subset} does not hold. Then there exists some $i_0$ such that $w_{i_0} \ne t_j$ for all $j$. Let $I$ denote the set of all indices $i$ such that $w_i = w_{i_0}$, and write $K = |I|$. Note that $K < 2^M < \text{char}(\mathbb F)$. Let $p(X), q(X)$ be as in the previous section. Since $q(X) \ne 0$, to show that \eqref{LogUp} is not satisfied, it suffices to show that $p(X) \ne 0$. Straightforward calculation shows that $p(X)$ can be written in the form $$ p(X) = (X – w_{i_0})^{K-1} \varphi(X) + (X – w_{i_0})^{K} \psi(X)$$ where $$\textstyle \varphi(X) = K \left( \prod_{i \not \in I} (X – w_i) \right) \left( \prod_{j} (X – t_j) \right)$$ and $\psi(X)$ is a polynomial (which polynomial doesn’t matter). By $K-1$ applications of the product rule for differentiation (as per usual, we differentiate polynomials symbolically), we see that $$\textstyle p^{(K-1)}(w_{i_0}) = (K-1)! \, \varphi(w_{i_0}).$$ Recalling that $K$ is bounded by the characteristic, we see by inspection that $\varphi (w_{i_0}) \ne 0$ and consequently (by the same fact) that $p^{(K-1)}(w_{i_0}) \ne 0$. Thus $p^{(K-1)}(X) \ne 0$, and so $p(X) \ne 0$, and we’re done.
Fractional sumcheck via the GKR protocol
We saw above that, in order to show \eqref{LogUp} w.h.p., we need to show that $$\tag{Eval}\label{Eval} \sum_i \frac{1}{\alpha – w_i} = \sum_j \frac{m_j}{\alpha – t_j}$$ for some random $\alpha \in \mathbb{F}$. This is just a relationship in the field. To show it, the authors describe “fractional sumcheck”, which amounts to separately reducing each side to a single fraction, and then showing that these two fractions are equal.
The reduction of each side of the equation is expressed as a layered arithmetic circuit to which the GKR protocol can be applied. Imagine we want to reduce a sum $$ \sum_{b \in \mathcal B^N} \frac{p(b)}{q(b)},$$ where $\mathcal B = \{0,1\}$ and $p$ and $q$ are functions $\mathcal B^N \to \mathbb{F}$. Note that e.g. the right hand side of \eqref{Eval} can be written in this form by replacing the indices $j=0,\dots,2^N – 1$ of the multiplicities $m$ and the table $t$ with bitstrings $b \in \mathcal B^N$ and defining the functions $p$ and $q$ to give the numerators and denominators of the summands. Now define $N+1$ functions $$ p_k, q_k : \mathcal B^k \to \mathbb{F}, \qquad 0 \leq k \leq N,$$ by $p_N := p$, $q_N := q$ and $$ p_k (b) := p_{k+1}(0b) q_{k+1}(1b) + p_{k+1}(1b)q_{k+1}(0b),$$ $$q_k (b) := q_{k+1}(0b) q_{k+1}(1b)$$ for all $b \in \mathcal B^k$, where e.g. $1b$ denotes the bitstring of length $k+1$ obtained by prefixing $b$ with a $1$. Then the desired single fraction is the ratio of field elements (i.e. functions on $\mathcal B^0$) $p_0 / q_0$. Do the same for the other side of the equation, obtaining $p’_0 / q’_0$, and then check both sides are equal via $pq’ – qp’=0$ and $q \ne 0$, $q’ \ne 0$ (these last two are shown using the inverses of $q$ and $q’$, taken as inputs). The above defines a layered arithmetic circuit with wiring that is regular in the sense of the GKR protocol. This allows the satisfaction of the circuit to be efficiently verified without needing to materialize (or commit to) any of the intermediate values. For more on the GKR protocol, check out Thaler’s book, or instead this blogpost by Remco Bloemen.
The case of batch witness columns
LogUp works just as well for a batch of witness columns. We haven’t made that explicit in the above (contrary to the presentation of the papers) because it suffices to simply concatenate the witness columns and sum up their multiplicities.
Other works using the logarithmic derivative for lookups
As described in the introduction to the 2022 logUp paper, there was both existing and concurrent work using the logarithmic derivative for lookup arguments (they are on the reading list!):
Thank you to the exceptional team at Modulus Labs, Georg Wiese, Victor Sint Nicolaas, Hamish Ivey-Law and Ulrich Haböck for helpful discussions and suggestions (any errors are my own).
I recently enjoyed a talk by François Charton on “Transformers for maths, and maths for transformers” (recording). Charton investigates the application of transformer-based translation models to basic mathematical tasks, ranging from basic arithmetic to integer sequence completion and linear algebra. It is important to note that each of these problems is encoded symbolically, not numerically. For instance, a natural number is fed to the transformer as a series of symbols representing its digits (in some base), and these symbols have no prior meaning to the model. The task of the model is translate the sequence of symbols that encode the problem to the sequence of symbols that encode the solution, and the model is trained on generated pairs of example input and output “sentences”. Remarkably, the transformer excels are some of these tasks, e.g. determining the eigenvalues of 5×5 matrices. For arithmetic tasks, the transformer has no trouble determining which of a pair of rational numbers is the larger, but it absolutely refuses to learn to compute their sum, or even simplify a fraction. Charton further investigates the arithmetic inabilities of the transformer in “Can transformers learn the greatest common divisor?”.
After the talk, it occurred to me that the inability of a transformer model to learn the GCD is a problem of expressibility (model can’t express the algorithm), not of learnability (model could express it, but can’t learn it). This is because any transformer-based algorithm runs in time linear in (input length + output length), whereas the run-time of the best known algorithms for computing the GCD are super-linear (e.g. quadratic or quasilinear) in the input length.
(Note that I’m adopting a computational model in which the transformer is allowed only finite memory (as it is in practice). Thus the size of the attention matrix is bounded, and so each step of the model is O(1). In unbounded memory was possible, each step would be linear!)
Consider the case of the Euclidean algorithm. In the worst case, the Euclidean algorithm runs in time quadratic in the length $l$ of each of the inputs (as a strings of digits, in some base). But the run-time of the transformer is linear in $l$: it consumes the $\approx 2l$ input symbols, and after which it must immediately proceed to produce output tokens. The sequence of output tokens (as defined by the training set) is of length less than $l$ (being the digital representation of the GCD). So that’s $\approx 3l$ steps in total, which is too few. So the model “doesn’t have enough time” to emulate the Euclidean algorithm.
It might be countered that we don’t really care about the Euclidean algorithm, and that we were rather interested to see what the transformer would come up with. Perhaps a linear time algorithm could exist, after all. But zooming out from GCD, it seems that it would be interesting and not too difficult to find other problems with proven super-linear lower bounds on complexity, and argue that it would be impossible for a transformer to solve it.
So, how would we solve it?
(The stimulus for the above train of thought came from a question that Dave Horsley asked of François after the talk.)
Polynomials are formal sums. So in particular, $\mathbb{K}[x]$ is infinite-dimensional over $\mathbb{K}$, even if e.g. $\mathbb{K} = \mathbb{F}_2$, the field with two elements. This is true even though e.g. $x^2 – x$ is the zero function on $\mathbb{F}_2$, as you can check by substituting $0$ and $1$ for $x$.
Polynomial functions are functions e.g. on the field itself (or, more generally, on some object that can be locally parameterized by the field). But let’s simply consider $\mathrm{Poly}(\mathbb{K})$, the set of polynomial functions from the field to itself. $\mathrm{Poly}(\mathbb{K})$ is a ring with addition and multiplication given point-wise on function values. Any polynomial can be considered a polynomial function in the obvious manner, and this defines a surjection of rings: $$ \pi: \mathbb{K}[x] \to \mathrm{Poly}(\mathbb{K}).$$ In the case where $\mathbb{K}$ is a finite field, $\mathrm{Poly}(\mathbb{K})$ is a proper quotient of $\mathbb{K}[x]$ i.e. $\ker \pi \ne 0$. To see this, consider the multiplicative group $\mathbb{K}^\times$. Then $|\mathbb{K}^\times| = q – 1$, where $q = |\mathbb{K}|$. Therefore $a^{q-1} = 1$ for any $a \in \mathbb{K}^\times$, and so $a^q – a = 0$ for any $a \in \mathbb{K} = \mathbb{K}^\times \sqcup { 0 }$. We’ve shown therefore that the non-zero polynomial $x^q – x$ is in $\ker \pi$, since it is maps to the zero function on $\mathbb{K}$. This is just the generalization of our observation for $\mathbb{F}_2$, above.
In fact, we’ve found a generator for the kernel, i.e. $ \ker \pi = \left\langle x^q – x \right\rangle$. One way to see this is to check that the polynomial functions defined by first $q-1$ monomials are linearly independent as functions on $\mathbb{K}$, which can be done using the Vandermonde matrix and the $q-1$ distinct non-zero field elements at your disposal. Another way to see this, since we are working over a finite field, is to simply count the elements of the quotient $\mathbb{K}[x] / {\left\langle x^q – x \right\rangle}$ and of $\mathrm{Poly}(\mathbb{K})$. There are clearly $q^q$ elements in the quotient, but what about $\mathrm{Poly}(\mathbb{K})$? It turns out that $\mathrm{Poly}(\mathbb{K})$ consists of all functions $\mathbb{K} \to \mathbb{K}$. To see this, given any function on $\mathbb{K}$, just use Lagrange interpolation to build yourself a polynomial of degree $\lt q$ that matches the function at all points. There are $q^q$ functions $\mathbb{K} \to \mathbb{K}$, and so that’s the size of $\mathrm{Poly}(\mathbb{K})$. Thus the quotient $\mathbb{K}[x] / {\left\langle x^q – x \right\rangle}$ has the same number of elements as $\mathrm{Poly}(\mathbb{K})$. But we have a chain of surjections $$ \mathbb{K}[x] / {\left\langle x^q – x \right\rangle} \to \mathbb{K}[x] / {\ker \pi} \to \mathrm{Poly}(\mathbb{K}),$$ so $\ker \pi = \left\langle x^q – x \right\rangle$.
On the other hand, if the field $\mathbb{K}$ is infinite, then $\ker \pi$ is zero, i.e. polynomials over $\mathbb{K}$ and polynomial functions on $\mathbb{K}$ are isomorphic. To see this just show that the set of all monomials is linearly independent, using the Vandermonde matrix and the endless supply of distinct non-zero elements of $\mathbb{K}$.
The multivariate case is entirely analogous
All functions $\mathbb{K}^n \to \mathbb{K}$ are polynomial functions. To see this, just mimic the Lagrange interpolation of the univariate case (it’s sufficient to convince yourself that, given any point in $\mathbb{K}^n$, you can write down a polynomial function that takes the value 1 there, and the value 0 everywhere else). Thus, since there are $q^{q^n}$ functions $\mathbb{K}^n \to \mathbb{K}$, this is the size of $\mathrm{Poly}_n(\mathbb{K})$, the ring of polynomial functions on $\mathbb{K}^n$.
Now write $$ \pi: \mathbb{K}[x_1, \dots, x_n] \to \mathrm{Poly}_n(\mathbb{K})$$ for the obvious surjection of rings. Then it follows immediately from the univariate case that we have an inclusion of ideals $$ \left\langle x_i^q – x_i | i=1, \dots, n \right\rangle \subset \ker \pi.$$ Now notice that the quotient $$\mathbb{K}[x_1, \dots, x_n] / \left\langle x_i^q – x_i | i=1, \dots, n \right\rangle$$ has $q^{q^n}$ elements. This is the same number as above, and so we conclude that we’ve already found the full kernel, i.e. $$ \ker \pi = \left\langle x_i^q – x_i | i=1, \dots, n \right\rangle.$$
This paper (arXiv), authored by Petersen, Borgelt, Kuehne and Deussen, was accepted for NeurIPs 2022. It does one of my favourite things: it learns a discrete structure (in this case, a boolean circuit) via differentiable means. Logic gate networks came up in a recent ZKML discussion as a machine learning paradigm of interest: since boolean circuits are encodable as arithmetic circuits, proving inference runs of a logic gate network can be done without the loss of accuracy that is inherent in the quantization approach to making the more familiar neural nets amenable to ZK. In fact, the situation is more subtle than that: a logic gate network is in fact discretized before inference (just not by us), and there was necessarily a small loss in accuracy in that process. An important difference, however, is that logic gate networks have been designed with this discretization in mind, since this is exactly what needs to be done to make model inference fast on edge hardware. This post presents notes on a presentation on this topic and the questions that arose during the discussion.
What’s a deep differentiable logic gate network?
A differentiable logic gate network consists of multiple layers of “neurons” with random wiring: Each neuron has precisely two inputs and is a superposition of the possible binary logic gates: where the probabilities (in purple) are learned from the data (using the softmax parameterization).
During training, the logic gates operate on values in the interval $[0,1]$ via arithmetic expressions e.g. $$\mathrm{OR}(x,y) = x + y – xy,$$and the output of a neuron is the expected value, over all logic gates, of their respective outputs, i.e. it’s a sum of the outputs of each gate, weighted by the probability of that gate (the purple values). Post-training, the network is discretized to yield a boolean circuit by replacing each neuron with its most likely logic gate.
Novelty
The superposition of different architectural components (logic gates) via the softmax is, to the best of my knowledge, novel. Note that here, softmax is not an activation function. Moreover, it’s not similar to the use of softmax in attention, as the probabilities are independent of the current input.
Points of interest
Why all 16 possible gates?
There are 16 possible binary logic gates – just count the boolean functions of two variables. Even though a smaller variety of gates would suffice to express any boolean circuit, the authors allow all 16, and this at the expense of increasing the training time, since there are more outcomes in the softmax to parameterise. The authors talk about this in the paper themselves. However, very deep circuits are hard to learn in their regime, so this redundancy is purposeful here.
Deep(er) logic gate networks are hard to learn
The authors explain this in terms of vanishing gradients. I think the problem is more fundamental, having nothing to do with the gradient, per se. An expectation is taken at every neuron/node in the circuit, and the layering of these successive expectations means that the signal at the output layer is very diluted. It is interesting to reflect that what we really would like to do is perform a superposition over all possible circuits of some size. This is of course infeasible, since the number of such circuits would be astronomical. So the authors perform superpositions of logic gates at each node, instead. Since deep logic gate networks are hard to learn (the maximum depth used by the authors is 6 layers), the authors go wide: their largest network has 1M nodes on each layer!
The wiring is fixed
The wiring of the network is the pattern of connections from layer to layer. Familiar neural networks are often fully connected, so each neuron is connected to all neurons in the previous layer. For logic gate networks, this is not the case: each neuron receives precisely two inputs from the outputs of the previous layer. There are obviously a huge number of choices for how to wire two layers together. In the approach of the authors, for simplicity, the wiring is determined pseudo-randomly before training and fixed for all time.
The authors don’t count the connection information in the storage requirements for the model, since the connections are determined by the initial random seed. This isn’t wrong, but it’s worth remembering (as the authors themselves note) that any future approach that employs a more intelligent method of determining the wiring will need to store the connection information.
Learning the wiring would be better
Learning the wiring would likely mean (in my estimation) that the such wide layers wouldn’t be necessary: a huge number of random connections would no longer be required to find the favourable information flows from inputs to outputs. Learning the wiring would be a non-trivial optimisation problem, however, more complicated than e.g. general sparsity constraints since the number of inputs must be exactly two (not just a arbitrary small number).
Regression as well as classification?
The authors also undertake to demonstrate that logic gate networks, when appended with a learned affine transformation, are useful devices for regression. This is not without precedent, since e.g. sometimes random forests are used for regression. However, I think the core case of classification is compelling enough.
The “normalisation temperature” $\tau$
Outputs are grouped into equally sized groups corresponding to the classes of the classification, and the score for each class is the sum of its outputs. These sums need normalising, since the resultant “score vector” needs to be a distribution: it is compared to the target distribution (which is one-hot on the target class) using cross entropy. There is only one correct way to do this, namely normalize by the size of the groups. Instead, the authors normalize by a hyperparameter $\tau$, for which they perform a grid search. The beneficial side effect of varying the value of $\tau$ is to amplify or diminish the strength of the back propagation signal, and as such, it ends up playing the role of a learning rate (the hyperparameter that the authors identify as a learning rate is in fact fixed).
Surprisingly, no annealing!
It is common practice to use a “temperature” parameter in the softmax to progressively encourage the model to move towards making a one-hot decision – this is called annealing. Surprisingly, the authors choose not to do this, and perhaps they didn’t need to (see Discretization).
Discretization
The authors claim that, post-training, the model has learned an unambiguous choice of logic gate for each node; they are consequently able to discretize the network of superpositions into a boolean circuit. This of course damages the accuracy of the model. The authors report however that this lose of accuracy is less that 0.1% for MNIST.
(I was skeptical about the claim that the choice of logic gate would be unambiguous post training, but can confirm that this is indeed the case: after training the smaller MNIST model, >96% of all neurons on all layers were essentially one-hot (i.e. one outcome had probability >85%).
Relevance to ZKML
Logic gate networks belong to the broad family of approaches that are focussed on efficient inference for edge devices, which includes further model types that may be of interest for ZKML, such as binary neural nets, quantised weight networks and neural nets trained with sparsity constraints. The other feature that all such models have in common is that they sacrifice some accuracy for efficiency and are consequently never the latest and greatest in performance. However, logic gate networks in particular are still in the first stages of their development, and future directions for improvement are apparent and, in my opinion, feasible.
The most important future improvement will be lower redundancy. Logic gate networks (in their current state) are boolean circuits with a high degree of redundancy resulting from their learning process. Reducing this redundancy will be crucial for making such models useful beyong toy datasets. For example, about four million logic gates are required for a competitive logic gate network for MNIST. From the ZKML perspective, to prove an inference run of such a network, the output of each logic gate (a bit) needs to be encoded as a separate field element – they can’t be grouped together into a larger field element since bit-wise operations need to be verified. While this is not so onerous (depending on the proof system), this is still just a model for a toy dataset. What is needed is a method of learning with reduced redundancy, and this will hopefully be the result of future work.
Here is a nice simple example of bilinear pairing on an elliptic curve over a finite field. Different sorts of pairings exist – here we’ll construct a pairing that coincides with the Weil pairing. For simplicity, our construction will avoid talking about divisors on algebraic curves.
Consider the elliptic curve over $\mathbb{F}_7$ defined by the equation $$ y^2 = x^3 + 2.$$ There are nine solutions: $$ \{ \mathcal{O},\ (0, \pm 3),\ (3, \pm 1),\ (5, \pm 1),\ (6, \pm 1)\ \}. $$ The identity element $\mathcal O$ is a point at infinity corresponding to the vertical axis (it is a point of the projective plane). All the other points are elements of the affine plane $\mathbb{F}_7 \times \mathbb{F}_7$. These nine points form a group which we’ll denote by $\mathbb{G}$.
We can check that for any $P \in \mathbb{G}$, we have $3 P = \mathcal O$. The most elementary way to check this is by direct calculation: we need to check that $P + P = -P$ for each point $P$. Recalling the diagrammatic rule for computing $P+P$, we need to draw the tangent to the curve at $P$, and then find the other point of intersection with the curve (it turns out this geometric interpretation of point doubling works over prime fields as well). So let’s calculate the slope $s$ of the tangent at each point $P=(x,y)$: $$ s = \frac{\frac{\partial}{\partial x} RHS}{\frac{\partial}{\partial y} LHS} = \frac{\frac{\partial}{\partial x} (x^3 + 2)}{\frac{\partial}{\partial y} y^2} = \frac{3x^2}{2y}.$$ This gives us the following diagram:
The dashed blue lines indicate the tangents to the curve at each point. Check for yourself that if you follow any of these tangents (remembering to wrap around to the opposite side when you get to an edge!) then you don’t hit any other points, i.e. the point of tangency $P$ is the only point of the elliptic curve on the tangent line, meaning that the “other” point of intersection must be $P$ itself (this means it’s an intersection of “higher order”). So $P + P$ is equal to the reflection of $P$ through the line $y=0$, i.e. $-P$, and so $3 P = \mathcal O$, as claimed.
In fact, it turns out that $\mathbb{G} \cong \mathbb{Z}_3 \times \mathbb{Z}_3$ as groups; you can construct such an isomorphism yourself by setting e.g. $g_1 = (0,3)$ and $g_2 = (3, 1)$ and taking these as the generators of the two copies of $\mathbb{Z}_3$ in the direct product. Note that this choice of isomorphism is not canonical (i.e. there is nothing to justify this particular choice) but that’s fine for our purposes. All we really need is that any $g \in \mathbb{G}$ has a unique expression $g = a_1 g_1 + a_2 g_2$ as a $\mathbb{Z}_3$-linear combination of our chosen generators $g_1, g_2$.
We are finally in a position to define a bilinear pairing. There are various types of pairings. Here, we’ll construct the Weil pairing. Let $\mu$ be an abelian group, written multiplicatively. We want a map $ e: \mathbb{G} \times \mathbb{G} \to \mu $ that is bilinear, i.e. $$ e(g + g’, h) = e(g, h) \cdot e(g’, h), \quad e(g, h + h’) = e(g, h) \cdot e(g, h’), $$ for all $g, g’, h, h’ \in \mathbb{G}$, and alternating, i.e. $$ e(g, h) = e(h, g)^{-1} \quad \forall g, h \in \mathbb{G}.$$ Some further properties follow immediately. For example, using that $\mathcal{O} + \mathcal{O} = \mathcal{O}$, it follows from bilinearity that $$ e(g, \mathcal{O}) = e(\mathcal{O}, h) = 1 \in \mu,$$ and from this last property and the fact that $3 P = \mathcal{O}$ for all $P \in \mathbb{G}$, it follows that $$ e(g, h)^3 = 1 \quad \forall g, h \in \mathbb{G},$$ and so we might as well take $\mu = \mu_3$ to be the group of third roots of unity over $\mathbb{F}_7$. Note $\mathbb{F}_7$ in fact contains all its third roots of unity, since $2^3 \equiv 1$ modulo $7$.
So how many alternating, bilinear forms can be there be on $\mathbb{G}$? Up to a choice of third root of unity, just one! To see this, just use the bilinearity and alternation properties to check that $$ e(a g_1 + b g_2, c g_1 + d g_2) = e(g_1, g_2)^{ad – bc}, \quad \forall a,b,c,d \in \mathbb{Z}_3,$$ i.e. all such forms are given by some third root of unity $e(g_1, g_2)$ raised to the power of the determinant of the matrix of coefficients. And on the other hand, since we know that the determinant is an alternating multilinear function on matrix rows, we see that this definition really does give us an alternating bilinear form on $\mathbb{G}$. From uniqueness, we know that this pairing must in fact coincide (up to choice of root of unity) with the Weil pairing of our elliptic curve, since it too is alternating and bilinear.
What about the general case? The Weil pairing is defined on the “$r$-torsion” $E[r]$ of an elliptic curve, i.e. the subgroup of points $P$ such that $r P = \mathcal{O}$. In our example, $r=3$ and the $3$-torsion subgroup $E[3]$ coincides with the entire group $\mathbb{G}$ (this is rarely true). On the other hand, the group isomorphism $E[r] \cong \mathbb{Z}_r \times \mathbb{Z}_r$ holds in general, with the caveat that you’ll likely need to take an extension field (not a prime field) as your base field.
Is this construction useful? While the above construction might be instructive, it isn’t useful. In order to prove useful things about the pairing, the divisor-theoretic construction is much more useful, since it allows us to call on the theory of algebraic curves (and in fact this is needed to even prove that $\mathbb{G}$ is a group!). Furthermore, in order to actually calculate a Weil pairing using the determinant construction, it is necessary to express an arbitrary $g \in E[r]$ as a linear combination of the chosen generators (and this problem would be hard even if there was just one generator: that’s the discrete logarithm problem!). So there are good reasons for the definition of the Weil pairing in terms of divisors, after all.
It should also be noted that the (divisor-theoretic) construction of the Weil pairing is canonical, not requiring a choice of basis for $E[r]$ nor a choice of primitive root of unity.
Addendum #1: as an alternative to the slope/tangent method above for visually checking that each point has order $3$, you can check instead that the Hessian determinant $X (Y^2 – Z^2)$ of the homogenisation of the equation defining the elliptic cruve vanishes at each point, i.e. show that each point is a point of inflection. See Silverman’s The Arithmetic of Elliptic Curves, exercise III.3.9.
Addendum #2: The example above has been chosen so that everything can be calculated by hand. To work with other examples, or to check your work, Magma is a great help. Here is some example code for the above calculations, which you can plug into the online calculator:
K := GF(7); // the finite field with 7 elements
// The EC with equation y^2 = x^3 + 0*x + 2 over K
E := EllipticCurve([K | 0, 2]);
print E, "\n";
print "Number of points on the curve", #E, "\n";
// Creation of a point with given projective coordinates
P := E ! [6, -1, 1];
print "The order of each element:";
for P in Points(E) do
print "Element", P, "has order", Order(P);
end for;
print "\n";
print "Point doubling:";
for P in Points(E) do
print "2", P, "=", P+P;
end for;
print "\n";
print "Find a decomposition of E as a product of finite cyclic groups:";
AbelianGroup(E);
print "\n";
print "Calculate the Weil pairing:";
for P in Points(E) do
for Q in Points(E) do
P, "paired with", Q, "=", WeilPairing(P, Q, 3);
end for;
end for;
The appearance of an elliptic curve from the point of view of the affine $(x,y)$ plane is familiar to us, but leaves us wondering what the curve might look like near the point at infinity (i.e. the identity element $\mathcal{O}$). This is not merely of visual interest, as it allows one to see directly that e.g. a line that is vertical in the $(x,y)$ plane has a pole of order 2 at the identity (even though it also intersects the curve at that point). The divisors of such linear functions play a crucial role in e.g. the computation of the Weil pairing.
Here is a first example of an elliptic curve over a finite field where you can work everything out by hand.
Consider the elliptic curve defined by the equation $$ y^2 = (x-1)(x-2)(x-3) $$ over the field $\mathbb{F}_5$. Multiplying out the right hand side, we see that (over $\mathbb{F}_5$), the right hand side (“RHS”) is $x^3 – x^2 + x – 1$. So our equation is not in Weierstrass form, but that’s fine. It’s still defines an elliptic curve. Note that we know immediately that it is non-singular, since the roots of the RHS are distinct.
It’s easy to find all the solutions $(x,y)$ to our equation by hand – just consider each possible value for $x \in \mathbb{F}_5$, calculate the RHS, and set $y = \pm \sqrt{RHS}$, if such $y$ exist. So we first need to know which values in $\mathbb{F}_5$ are squares:
Thus the points on our elliptic curve are $$ (0,2), (0,3), (1,0), (2,0), (3,0), (4,1), (4,4), \mathcal{O}.$$ The point $\mathcal{O}$ is the solution at infinity: this is the one extra solution $(0:0:1)$ that arises when the equation defining the elliptic curve is homogenized, and solutions in the projective plane are permitted. The other solutions live in the “affine” $(x,y)$ plane.
The nice thing about working over an unextended finite field like $\mathbb{F}_5$ is that it is still “1-dimensional”, so the affine solutions $(x,y)$ can be depicted on a 2-dimensional diagram like the following:
Fortunately, the familiar geometric description of the group operation on elliptic curves in terms of line intersections still works (why?). That is, any two points can be added by drawing a line through them, finding the third point of intersection, and reflecting through the line $y=0$, and the point $\mathcal{O}$ corresponds to the vertical direction and is the identity element of the group.
For example, it is immediate from this rule that $A+B=C$. Remembering that lines wrap-around our diagram (which is actually a torus), what do you think $C+D$ is equal to? (Hint: it’s the next letter of the alphabet).
As in the case over $\mathbb{R}$:
If a vertical line passes through two distinct affine points such as $(0,2)$ and $(0,3)$, then (since it also intersects with $\mathcal{O}$ in the projective plane) these points are inverses of one another w.r.t. the group operation. (We’ve labelled $-D, -E$ to reflect this.)
If a vertical line hits a single affine point (e.g. the line $x=1$) then this point is its own inverse.
Thus $A, B, C$ are all group elements of order 2.
Amusingly, the geometric rule for point doubling using tangents still works, as well. The slope of the tangent at a point $(x,y)$ on our elliptic curve can be calculated in the usual way. $$ s = \frac{\frac{\partial}{\partial x} RHS}{\frac{\partial}{\partial y} LHS} = \frac{3x^2 – 2x + 1}{2y}.$$ These slopes are depicted on our diagram with dashed blue lines. Following these tangents, you can immediately verify that $$ \pm E + \pm E = B, \qquad \pm D + \pm D = B,$$ and so $\pm D, \pm E$ have order $4$ as group elements.
The orders of our group elements are enough to conclude that our group (call it $\mathbb{G}$) is isomorphic to $\mathbb{Z}_2 \times \mathbb{Z}_4$. Indeed, since $A+B=C$ and $A+D=E$ (to check, just follow the lines!) we have that $$ \begin{array}{ccc} \mathcal{O} & \mapsto & (0,0) \\ A & \mapsto & (1,0) \\ B & \mapsto & (0,2) \\ C & \mapsto & (1,2) \\ \pm D & \mapsto & (0,\pm 1) \\ \pm E & \mapsto & (1,\pm 3)\\ \end{array} $$ is an isomorphism of groups $\mathbb{G} \rightarrow \mathbb{Z}_2 \times \mathbb{Z}_4.$
Here are the slides from a talk I gave the Sydney machine learning meetup on Siegelmann and Sontag’s paper from 1995 “On the Computational Power of Neural Nets”, showing that recurrent neural networks are Turing complete. It is a fantastic paper, though it is a lot to present in a single talk. I spent some time illustrating what the notion of a 2-stack machine, before focussing on the very clever Cantor set encoding of the authors.
I gave a talk last night at the Berlin machine learning meetup on learning graph embeddings in hyperbolic space, featuring the recent NIPS 2017 paper of Nickel & Kiela. Covered are:
An illustration of why the Euclidean plane is not a good place to embed trees (since circle circumference grows only linearly in the radius);
Extending this same argument to higher dimensional Euclidean space;
An introduction to the hyperbolic plane and the Poincaré disc model;
A discussion of Rik Sarkar’s result that trees embed with arbitrarily small error in the hyperbolic plane;
A demonstration that, in the hyperbolic plane, circle circumference is exponential in the radius (better written here);
A review of the results of Nickel & Kiela on the (transitive closure of the) WordNet hypernymy graph;
Some thoughts on the gradient optimisation (perhaps better written here).
Nickel & Kiela had a great paper on embedding graphs in hyperbolic space at NIPS 2017. They work with the Poincaré ball model of hyperbolic space. This is just the interior of the unit ball, equipped with an appropriate Riemannian metric. This metric is conformal, meaning that the inner product on the tangent spaces on the Poincare ball differ from that of the (Euclidean) ambient space by only a scalar factor. This means that the hyperbolic gradient $\nabla_u$ at a point $u$ can be obtained from the Euclidean gradient $\nabla^E_u$ at that same point just by rescaling. That is, you pretend for a moment that your objective function is defined in Euclidean space, calculate the gradient as usual, and just rescale. This scaling factor depends on the Euclidean distance $r$ of $u$ from the origin, as depicted below:
So far, so good. What the authors then do is simply add the (rescaled) gradient to obtain the new value of the parameter vector, which is fine, if you only take a small step, and so long as you don’t accidentally step over the boundary of the Poincaré disc! A friend described this as the Buzz Lightyear update (“to infinity, and beyond!”). While adding the gradient vector seems to work fine in practice, it does seem rather brutal. The root of the “problem” (if we agree to call it one) is that we aren’t following the geodesics of the manifold – to perform an update, we should really been applying the exponential map at that current point to the gradient vector. Geodesics on the Poincaré disc look like this:
that is, they are sections of circles that intersect the boundary of the Poincaré disc at right angles, or diameters (the latter being a limiting case of the former). With that in mind, here’s a picture showing how the Buzz Lightyear update on the Poincaré disc could be sub-optimal:
The blue vector $\nabla_u$ is the hyperbolic gradient vector that is added to $u$, taking us out of the Poincaré disc. The resulting vector is then pulled back (along the ray with the faintly-marked origin) until it is within the disc by some small margin, resulting in the new value of the parameter vector $u^\textrm{new}$. On the other hand, if you followed the geodesic from $u$ to which the gradient vector is tangent, you’d end up at the end of the red curve. Which is quite some distance away.
I recently needed to demonstrate this fact to an audience that I could not assume would be familiar with Riemannian geometry, and it took some time to find a way to do it! You can use the HyperRogue game, which takes place on a tiling of the Poincaré disc. The avatar moves across the Poincaré disc (slaying monsters and collecting treasure) by stepping from tile to tile. It is a pretty impressive piece of software, and you can play it on various devices for small change. Below are four scenes from the game. This image was taken from the interesting paper on HyperRogue by Kopczyński et al., cited at bottom.
As a proxy for proving that the growth rate was exponential, just count the number of tiles that were accessible (starting from the centre tile) in N steps and no less. This gives the sequence 1, 14, 28, 49, 84, 147, 252, 434, 749, … . Plotting this values gives evidence enough.
The authors of the paper do a more thorough job, obtaining a recurrence relation for the sequence and using this to derive the base of the exponential growth (which comes out at about $\sqrt{3}$.
[1] Kopczyński, Eryk; Celińska, Dorota; Čtrnáct, Marek. “HyperRogue: playing with hyperbolic geometry”. Proceedings of Bridges 2017: Mathematics, Music, Art, Architecture, Culture (2017).
[These are the notes from a talk I gave at the seminar]
Hierarchical softmax is an alternative to the softmax in which the probability of any one outcome depends on a number of model parameters that is only logarithmic in the total number of outcomes. In “vanilla” softmax, on the other hand, the number of such parameters is linear in the number of total number of outcomes. In a case where there are many outcomes (e.g. in language modelling) this can be a huge difference. The consequence is that models using hierarchical softmax are significantly faster to train with stochastic gradient descent, since only the parameters upon which the current training example depend need to be updated, and less updates means we can move on to the next training example sooner. At evaluation time, hierarchical softmax models allow faster calculation of individual outcomes, again because they depend on less parameters (and because the calculation using the parameters is just as straightforward as in the softmax case). So hierarchical softmax is very interesting from a computational point-of-view. By explaining it here, I hope to convince you that it is also interesting conceptually. To keep things concrete, I’ll illustrate using the CBOW learning task from word2vec (and fasttext, and others).
The CBOW learning task
The CBOW learning task is to predict a word $w_0$ by the words on either side of it (its “context” $C$).
We are interested then in the conditional distribution $P(w|C)$, where $w$ ranges over some fixed vocabulary $W$.
This is very similar to language modelling, where the task is to predict the next word by the words that precede it.
CBOW with softmax
One approach is to model the conditional distribution $P(w|C)$ with the softmax. In this setup, we have:
where $Z_C = \sum_{w’ \in W} {\text{exp}({\beta_{w’}}^T \alpha_C)}$ is a normalisation constant, $\alpha_C$ is the hidden layer representation of the context $C$, and $\beta_w$ is the second-layer word vector for the word $w$. Pictorially:
The parameters of this model are the entries of the matrices $\alpha$ and $\beta$.
Cross-entropy
For a single training example $(w_0, C)$, the model parameters are updated to reduce the cross-entropy $H$ between the distribution $\hat{y}$ produced by the model and the distribution $y$ representing the ground truth:
Because $y$ is one-hot at $w_0$ (in this case, the word “time”), the cross-entropy reduces to a single log probability:
$$ H(y, \hat{y}) := – \sum_{w \in W} {y_w \log \hat{y}_w = – \log P(w_0|C).$$
Note that this expression doesn’t depend on whether $\hat{y}$ is modelled using the softmax or not.
Optimisation of softmax
The above expression for the cross entropy is very simple. However, in the case of the softmax, it depends on a huge number of model parameters. It does not depend on many entries of the matrix $\alpha$ (only on those that correspond to the few words in the context $C$), but via the normalisation $Z_C$ it depends on every entry of the matrix $\beta$. The number of these parameters is proportional to $|W|$, the number of vocabulary words, which can be huge. If we optimise using the softmax, all of these parameters need to be updated at every step.
Hierarchical softmax
Hierarchical softmax provides an alternative model for the conditional distributions $P(\cdot|C)$ such that the number of parameters upon which a single outcome $P(w|C)$ depends is only proportional to the logarithm of $|W|$. To see how it works, let’s keep working with our example. We begin by choosing a binary tree whose leaf nodes can be made to correspond to the words in the vocabulary:
Now view this tree as a decision process, or a random walk, that begins at the root of the tree and descents towards the leaf nodes at each step. It turns out that the probability of each outcome in the original distribution uniquely determines the transition probabilities of this random walk. At every internal node of the tree, the transition probabilities to the children are given by the proportions of total probability mass in the subtree of its left- vs its right- child:
This decision tree now allows us to view each outcome (i.e. word in the vocabulary) as the result of a sequence of binary decisions. For example:
$$ P(\texttt{“time”}|C) = P_{n_0}(\text{right}|C) P_{n_1}(\text{left}|C) P_{n_2}(\text{right}|C),$$
where $P_{n}(\text{right}|C)$ is the probability of choosing the right child when transitioning from node $n$. There are only two outcomes, of course, so:
$$P_{n}(\text{right}|C) = 1 – P_{n}(\text{left}|C).$$
These distributions are then modelled using the logistic sigmoid $\sigma$:
$$ P_{n}(\text{left}|C) = \sigma({\gamma_n}^T \alpha_C),$$
where for each internal node $n$ of the tree, $\gamma_n$ is a coefficient vector – these are new model parameters that replace the $\beta_w$ of the softmax. The wonderful thing about this new parameterisation is that the probability of a single outcome $P(w|C)$ only depends upon the $\gamma_n$ of the internal nodes $n$ that lie on the path from the root to the leaf labelling $w$. Thus, in the case of a balanced tree, the number of parameters is only logarithmic in the size $|W|$ of the vocabulary!
Which tree?
J. Goodman (2001)
Goodman (2001) uses 2- and 3-level trees to speed up the training of a conditional maximum entropy model which seems to resemble a softmax model without a hidden layer (I don’t understand the optimisation method, however, which is called generalised iterative scaling). In any case, the internal nodes of the tree represent “word classes” which are derived in a data driven way (which is apparently elaborated in the reference [9] of the same author, which is behind a paywall).
F. Morin & Y. Bengio (2005)
Morin and Bengio (2005) build a tree by beginning with the “is-a” relationships for WordNet. They make it a graph of words (instead of word-senses), by employing a heuristicFelix, and make it acyclic by hand). Finally, to make the tree binary, the authors repeatedly cluster the child nodes using columns of a tf-idf matrix.
A. Mnih & G. Hinton (2009)
Mnih & Hinto (2009) use a boot-strapping method to construct binary trees. Firstly they train their language model using a random tree, and afterwards calculate the average context vector for every word in the vocabulary. They then recursively partition these context vectors, each time fitting a Gaussian mixture model with 2 spherical components. After fitting the GMM, the words are associated to the components, and this defines to which subtree (left or right) a word belongs. This is done in a few different ways. The simplest is to associate the word to the component that gives the word vector the highest probability (“ADAPTIVE”); another is splitting the words between the two components, so that the resulting tree is balanced (“BALANCED”). They consider also a version of “adaptive” in which words that were in a middle band between the two components are placed in both subtrees (“ADAPTIVE(e)”), which results not in a tree, but a directed acyclic graph. All these alternatives they compare to trees with random associations between leaves and words, measuring the performance of the resulting language models using the perplexity. As might be expected, their semantically constructed trees outperform the random tree. Remarkably, some of the DAG models perform better than the softmax!
Mikolov et al. (2013)
The approaches above all use trees that are semantically informed. Mikolov et al, in their 2013 word2vec papers, choose to use a Huffman tree. This minimises the expected path length from root to leaf, thereby minimising the expected number of parameter updates per training task. Here is an example of the Huffman tree constructed from a word frequency distribution:
What is interesting about this approach is that the tree is random from a semantic point of view.
In their book “Perceptrons” (1969), Minsky and Papert demonstrate that a simplified version of Rosenblatt’s perceptron can not perform certain natural binary classification tasks, unless it uses an unmanageably large number of input predicates. It is easy to show that with sufficiently many input predicates, a perceptron (even on this type) can perform any classification with perfect accuracy (see page 3 of the notes below). The contribution of Minsky and Papert is to show that meaningful restrictions on the type of input predicates hamper the expressive ability of the perceptron to such a degree that it is unable to e.g. distinguish connected from disconnected figures, or classify according to whether the number of active pixels is odd or even. The former has a simple picture proof, whereas the crucial ingredient for the latter is the action of a permutation group on the retina (i.e. the input array) of the perceptron.
The book is an engaging and instructive read – not only is it peppered with the author’s opinions and ideas, but it includes also enlightening comments on how the presented ideas originated, and why other ideas that occurred to the authors didn’t work out. The book still bears the marks of it’s making, so to speak.
Controversy
The publication of the first edition in 1969 is popularly credited with bringing research on perceptrons and connectionism in general to a grinding halt. The book is held to be unjust, moreover. The “perceptrons”, which Minsky and Papert prove to be so limited in expressive power, were in fact only a very simplified version of what practitioners then regarded as a perceptron. A typical perceptron (unlike those of Minsky and Papert) might include more layers, feedback loops, or even be coupled with another perceptron. All these variations are described in Rosenblatt’s book “Principles of Neurodynamics” (1962). This is put very well (and colourfully!) by Block in his review of the book (1970):
Thus, although the authors state (p. 4, lines 12-14) “we have agreed to use the name ‘perceptron’ in recognition of the pioneer work of Frank Rosenblatt.”, they study a severely limited class of machines from a viewpoint quite alien to Rosenblatt’s. As a result, the title of the book, although generous in intent, is seriously misleading to the naive reader who wants to find out something about the general class of Perceptrons.
In summary then, Minsky and Papert use the word perceptron to denote a restricted subset of the general class of Perceptrons. They show that these simple machines are limited in their capabilities. This approach is reminiscent of the möhel who throws the baby into the furnace, hands the father the foreskin and says, “Here it is; but it will never amount to much.”
Despite these serious criticisms, it should be noted that Block (himself a trained mathematician) was full of praise for the “mathematical virtuosity” exhibited by Minsky and Papert in their book.
As to whether the book alone stopped research into perceptrons is hard to judge, particularly given it’s impact is confounded by the tragic death of Rosenblatt (at age 41) only two years later.
Suppose you have a model that depends on real-valued parameters, and that you would like to constrain these parameters to be non-negative. For simplicity, suppose the model has a single parameter $a \in \mathbb R$. Let $E$ denote the error function. To constrain $a$ to be non-negative, parameterise $a$ as the square of a real-valued parameter $\alpha \in \mathbb R$:
$$a = \alpha^2, \quad \alpha \in \mathbb R.$$
We can now minimise $E$ by choosing $\alpha$ without constraints, e.g. by using gradient descent. Let $\lambda > 0$ be the learning rate. We have
Here we derive updates rules for the approximation of a row stochastic matrix by the product of two lower-rank row stochastic matrices using gradient descent. Such a factorisation corresponds to a decomposition
$$ p(n|m) = \sum_k p(n|k) \cdot p(k|m) $$
Both the sum of squares and row-wise cross-entropy functions are considered.
I learnt of the 1944 experiment of Heider and Simmel in the Machine Intelligence workshop at NIPS 2016. The experiment involved showing subjects the video below, and asking them to describe what they saw. If you’ve watched the video, you’ll not be surprised to learn that most of the subjects anthropomorphised the geometric objects (i.e. they described them as humans, or their actions and intentions in human terms). In the talk at the workshop, this was offered as evidence that humans have a tendency to anthropomorphise, the implication then being that it is not hard to trick users into believing that e.g. a chat bot is a real person. While the implication might indeed be true, I don’t think the experiment of Heider and Simmel shows this at all. In my view, the reason that viewers anthropomorphise the shapes in the video is because they know that the video is made by human beings, and as such is created with intention. When you watch this video, you are participating in an act of communication, and the natural question to ask is: “what are the creators trying to communicate to me?”. For contrast, imagine that you are sitting in the bath and you have a few triangular shapes that float. If you float the shapes on the water and watch them for a while as they randomly (without expression of intent!) bob about, are you likely to anthropomorphise them? I’d say you are much less likely to do so.
Non-negative matrix factorisation (NMF) learns to reconstruct samples as a superposition of their constituent parts. In the paper of Lee and Seung (1999) that popularised NMF, this is called a “parts-based” representation. This is illustrated in that paper by applying NMF to encodings of images of faces, where NMF seems to decompose the faces into a collage of eigen-eyebrows and eigen-noses. Visual demonstrations are fantastic for conveying ideas, but in this particular instance, the clarity is compromised by the inherent noisiness of real-world facial images. The images are drawn, moreover, from the CBCL dataset, which has a non-commercial license. In order to get around this problem, and to have an even clearer visual demonstration of the “parts-based” decomposition provided by NMF for my course at DataCamp, I created a synthetic image dataset, where each image is of a single digit of a LCD display, as on a clock radio. The parts learned by NMF are then the individual “cells” of the LCD display.
You can construct this dataset yourself, using the code below. The collection of images is encoded as a 2d array of non-negative values. Each row corresponds to an image, and each column corresponds to a pixel. The non-negative entries represent the whiteness of the pixel, encoded here as a value between 0 and 1.
Alternatives
The standard bars provide a similar (but more apparently synthetic) image dataset for learning the parts of images. See, for example, the references given in Spratling (1996).
Another great visual dataset could be built from black-and-white images of the 52 playing cards in a deck. NMF would then learn the ranks (i.e. ace, 2, 3, …, ) and the suits (i.e. spades, hearts, …) as parts, and reconstruct playing cards from these. I haven’t done this.
Yet another great example dataset could be constructed using images of a piano keyboard, or perhaps just an octave range, colouring the keys according to how often they are pressed during a song. NMF should then be able to learn the chords as parts. The midi files to construct this dataset could be obtained from the Mutopia project, for example. I haven’t done this either.
Having trained a model, it is natural to want to understand how it works. An intuitively appealing approach is to consider data samples that maximise the activation of a hidden unit, and to take the common input features of these samples as an indication of what that unit has learned to recognise. However, as we’ll see below, it is a misconception to speak of hidden units if:
there is no non-linearity on the hidden layer;
the weights connecting the layers are unconstrained; and
the model is trained using (stochastic) gradient descent or similar.
In such a scenario, the hidden feature space must instead be considered as a whole.
Summary
Consider the task of factorising a matrix $ X $ as a product of matrices $ X \cong A^T B $ with some fixed inner dimension $ k $. The model parameters are pairs of matrices $ (A, B) $ with the appropriate dimensions, and the image of an input vector $ x $ on the hidden layer is given by $ Ax $. To consider this vector $ Ax $ in terms of hidden unit activations is to fix a co-ordinate system in the hidden feature space, and to measure the displacement of the vector along each co-ordinate axis. If $ E_1, \dots , E_k $ denote the unit vectors corresponding to the chosen co-ordinate system, then the displacements are given by the inner products
\begin{equation*} \langle Ax, E_i \rangle, \quad i = 1, \dots, k. \end{equation*}
We show below that if $ P $ is any rotation of the hidden feature space, then the model parameters $ (PA, PB) $ are just as likely as $ (A, B) $ to result in the factorisation of a fixed matrix $ X $ and that which of these occurs depends only on the random initialisation of gradient descent. Thus the hidden unit activations might just as likely have been given by
\begin{equation*} \langle (PA)x, E_i \rangle, \quad i = 1, \dots, k. \end{equation*}
The hidden unit activations given by 1 and 2 can be very different indeed. In fact, since $ P $ is an orthogonal transformation, we have
\[
\langle (PA)x, E_i \rangle = \langle Ax, P^T E_i \rangle, \quad i = 1, \dots, k
\]
(see e.g. here). Thus the indeterminacy of the model parameters, i.e. $ (A, B) $ vs. $ (PA, PB) $, might equivalently be thought of as an indeterminacy in the orientation of the co-ordinate system, i.e. the $ E_i $ vs. the $ P^T E_i $. The choice of orientation of co-ordinate basis is completely arbitrary, so speaking of hidden unit activations makes no sense at all.
The above holds more generally for $ P $ an orthogonal transformation of the hidden feature space, i.e. for $ P $ a composition of rotations and reflections.
Szegedy et al.
None of the above is new. For example, it was stated by Szegedy et al. in an empirical study of the interpretability of hidden units. We are demonstrating, step-by-step, a statement of theirs (which was about word2vec):
… word representations, where the various directions in the vector space representing the words are shown to give rise to a surprisingly rich semantic encoding of relations and analogies. At the same time, the vector representations are stable up to a rotation of the space, so the individual units of the vector representations are unlikely to contain semantic information.
Matrix factorisation and unit activation
Given a matrix $ X $ and an inner dimension $ k $, the task of matrix factorisation is to learn two matrices $ A $ and $ B $ whose product approximates $ X $:
The parameter space consists of the entries of the matrices $ A $ and $ B $. The hidden feature space, on the other hand, is the k-dimensional space containing the columns of $ A $ and $ B $.
Error function
To train a matrix factorisation model using gradient descent, the model parameters are repeatedly updated using the gradient vector of the error function. An example error function $ E $ could be
Notice that this choice of error function doesn’t depend directly on the pair of matrices $ (A, B) $, but rather only on their product $ AB $, i.e. only on the approximation $ AB $ of $ X $. This is true of any error function $ E_X $, because error functions depend only on inputs and outputs.
Orthogonal transformations of the hidden feature space
Recall that orthogonal transformations of a space are just compositions of rotations and reflections about hyperplanes passing through the origin. Considered as matrices, orthogonal transformations are defined by the property that their product with their transpose gives the identity matrix. Using this property, it can be seen that an orthogonal transformation of the hidden feature space defines an orthogonal transformation of the parameter space by acting simultaneously on the column vectors of the matrices. If $ O_k $ and $ O_{(m+n)k} $ denote the groups of orthogonal transformations on the hidden feature space and the parameter space, respectively, then:
Contour lines of the gradient
The effect of this block-diagonal orthogonal transformation on the parameter space corresponds to multiplying the matrices $ A $ and $ B $ on the left by the orthogonal transformation $ P $ of the feature space, i.e. it effects $ (A, B) \mapsto (PA, PB) $. Notice that $ (A, B) $ and $ (PA, PB) $ yield the same approximation to the original matrix $ X $, since:
\[
(PA)^T (PB) = (A^T P^T) (PB) = A^T (P^T P) B = AB.
\]
Thus $ E_X (A, B) = E_X (PA, PB) $, so the orthogonal transformations $ P $ of the hidden feature space trace out contour lines of $ E_X $ in the parameter space. Now the gradient vector is always perpendicular to the contour line, so the sequence of points in the parameter space visited during gradient descent preserve the orientation of the hidden feature space set at initialisation (see here, for example). So if gradient descent of $ E_X $ starting at the initial parameters $ (A^{(0)}, B^{(0)}) $ converges to the parameters $ (A, B) $, and you’d prefer that it instead converged to $ (PA, PB) $, then all you need to do is start the gradient descent over again, but this time with the initial parameters $ (PA^{(0)}, PB^{(0)}) $. We thus see that the matrices $ (A, B) $ that our matrix factorisation model has learned are only determined up to an orthogonal transformation of the hidden feature space, i.e. up to a simultaneous transformation of their columns.
Gradient descent methods
The above statements continue to hold in the case of stochastic gradient descent, where the error function $ E_X $ is not fixed but rather defined by varying mini-tasks (an instance being e.g. word2vec). Such error functions still don’t depend upon hidden layer values, so as above their gradient vectors are perpendicular to the contour lines traced out by the orthogonal transformations of the hidden layer. Thus the updates performed in stochastic gradient descent also preserve the original orientation of the feature space.
Initialisation
How likely is it that initial parameters, transformed via an orthogonal transformation as above, ever occur themselves as initial parameters? In order to conclude that the orientation of the co-ordinate system on the hidden layer is completely arbitrary, we need it to be precisely as likely. Thus if $ \pi $ denotes the probability distribution on the parameter space from which the initial parameters are drawn, we require
for any initial parameters $ ( A^{(0)}, B^{(0)} ) $ and any orthogonal transformation $ P $ of the hidden feature space.
This is not the case with word2vec, where each parameter is drawn independently from a uniform distribution. However, it remains true that for any choice of initial parameters, there will still be any number of possible orientations of the co-ordinate system, but for some choices of initial parameters there is less freedom than for others.
Appendix: What about GloVe?
GloVe performs weighted matrix factorisation with bias terms, so the above should apply. The weighting is just a modified error function, and the bias terms are not hidden features and so are left unmodified by its orthogonal transformations. Like word2vec, GloVe initialises each parameter with independent samples from uniform distribution, so there are no new problems there. The real problem with applying the above analysis to GloVe is that the implementation of Adagrad used makes the learning regime dependent on the choice of basis of the hidden feature space (see e.g. here). This doesn’t mean that the hidden unit activations of GloVe make sense, it just means that GloVe is less amenable to theoretical arguments like those above and needs to be considered empirically e.g. in the manner of Szegedy et al.
Adagrad is a learning regime that maintains separate learning rates for each individual model parameter. It is used, for instance, in GloVe (perhaps incorrectly), in LightFM, and in many other places besides. Below is an example showing that Adagrad models evolve in a manner that depends upon the choice of co-ordinate system (i.e. orthonormal basis) for the parameter space. This dependency is no problem when the parameter space consists of many one-dimensional, conceptually unrelated features lined up beside one another, because such parameter spaces have only one natural orientation of the co-ordinate axes. It is a problem, however, for the use of Adagrad in models like GloVe and LightFM. In these cases the parameter space consists of many feature vectors (of dimension, say, 100) concatenated together. A learning regime should not depend upon the arbitrary choice of orthonormal basis in this 100-dimensional feature space.
For feature spaces like these, I would propose instead maintaining a separate learning rate for each feature vector (for example, in the case of GloVe, there would be one learning rate per word vector per layer). The learning rate of a feature vector would dampen the initial learning rate by the accumulation of the squared norms of the previous gradient updates of the feature vector. The evolution of Adagrad would then be independent of the choice of basis in the feature space (as distinct from the entire parameter space). In the case of GloVe this means that a simultaneous rotation of all the word vectors in both layers during training does not alter the resulting model. This proposal would have the further advantage of greatly reducing the number of learning rates that have to be stored in memory. I don’t know if this proposal would have regret minimisation properties analogous to Adagrad. I haven’t read the original paper of Duchi et al. (2011), and what I am proposing might be subsumed there by the full-rank case (thanks to Alexey Rodriguez for pointing this out). Perhaps a block diagonal matrix could be used instead of a diagonal one.
Update: Minh + Kavukcuoglu seem to have adopted the same point of view in Learning word embeddings efficiently with noise-contrastive estimation (2013). Thanks to Matthias Leimeister for this.
We show that if the contour lines of a function are symmetric with respect to some rotation or reflection, then so is the evolution of gradient descent when minimising that function. Rotation of the space on which the function is evaluated effects a corresponding rotation of each of the points visited under gradient descent (similarly, for reflections).
This ultimately comes down to showing the following: if $ f: \mathbb{R}^N \to \mathbb{R} $ is the differentiable function being minimised and $ g $ is a rotation or reflection that preserves the contours of $ f $, then
\begin{equation}\label{prop} \nabla |_{g(u)} f = g ( \nabla |_u f) \end{equation}
for all points $ u \in \mathbb{R}^N $.
Examples
We consider below three one-dimensional examples that demonstrate that, even if the function $ f $ is symmetric with respect to all orthogonal transformations, it is necessary that the transformation $ g $ be orthogonal in order for the property (\ref{prop}) above to hold.
I prepared the following one-page overview of the short-time Fourier transform for a recent talk, perhaps it’ll be useful to others. For justification of e.g. the conjugate symmetry of the Fourier coefficients or a discussion of aliasing, see here.
We aim to identify the assumptions that are implicit in the sampling of a continuous-time signal and in the subsequent application of the discrete Fourier transform (DFT). In particular, we consider the following questions:
When does the sampling of periodic continuous-time signal result in a periodic discrete-time signal?
When the resulting discrete-time signal is periodic, what is its frequency in samples/second?
Which continuous-time frequencies coincide in discrete time, and what does the “frequency spectrum” in discrete-time look like?
To which periodic discrete-time signals can the discrete Fourier transform be applied to without losing information?
We furthermore show that the DFT interchanges point-wise and convolution products in the time- and frequency- domains, and thereby express the DFT to Pontryagin duality for finite cycle groups.
I talked about the above (skipping many details!) at a recent talk.
Non-negative matrix factorisation (NMF) is a dimension reduction technique that is commonly applied in a number of different fields, for example:
in topic modelling, applied to the document x word matrix;
in speech processing, applied to the matrix of magnitude spectrograms of framed audio;
in recommendation systems, applied to the user x item interaction matrix.
Due to its non-negativity constraint, it has the wonderful property of decomposing a objects as an additive combination of (often very meaningful) parts. However, as with all unsupervised learning tasks, it is sensitive to the relative scale of different features.
The fundamental problem is that the informativeness of a feature need not be related to its scale. For example, when processing speech, the highest-energy components of a magnitude spectrogram are those of the least perceptual importance! So when NMF decides which information to discard into order to achieve a low-rank factorisation that minimises the error function, it can be the signal, not the noise, that is sacrificed. This problem is not unique to NMF, of course: PCA retains those dimensions of the sample cloud that have the greatest variance.
It is in general better to learn a feature representation jointly with the downstream task, so that the model learns to scale features according to their informativeness for the task. If NMF is for some reason still desirable, however, it is possible to better control the information loss by choosing an appropriate measure of the matrix factorisation error.
There are three common error functions used in NMF (all of which Bregman divergences): squared Euclidean, Kullback-Leibler (KL) and Itakura-Saito (IS). These are respectively quadratic, linear and invariant with respect to the feature scale. Thus, for example, NMF with the Euclidean error function gives strong preference to high-energy features, while NMF with the IS error function is agnostic to feature scale.
In these notes we study the rate of convergence of gradient descent in the neighbourhood of a local minimum. The eigenvalues of the Hessian at the local minimum determine the maximum learning rate and the rate of convergence along the axes corresponding to the orthonormal eigenvectors.
The paper Neural Word Embeddings as Implicit Matrix Factorization of Levy and Goldberg was published in the proceedings of NIPS 2014 (pdf). It claims to demonstrate that Mikolov’s Skipgram model with negative sampling is implicitly factorising the matrix of pointwise mutual information (PMI) of the word/context pairs, shifted by a global constant. Although the paper is interesting and worth reading, it greatly overstates what is actually established, which can be summarised as follows:
Suppose that the dimension of the Skipgram word embedding is at least as large as the vocabulary. Then if the matrices of parameters $(W, C)$ minimise the Skipgram objective, and the rows of $W$ or the columns of $C$ are linearly independent, then the matrix product $WC$ is the PMI matrix shifted by a global constant.
This is a really nice result, but it certainly doesn’t show that Skipgram is performing (even implicitly) matrix factorisation. Rather it shows that the two learning tasks have the same global optimum – and even this is only shown when the dimension is larger than the vocabulary, which is precisely the case where Skipgram is uninteresting.
The linear independence assumption
The authors (perhaps unknowingly) implicitly assume that the word vectors on one of the two layers of the Skipgram model are linearly independent. This is a stronger assumption than what the authors explicitly assume, which is that the dimension of the hidden layer is at least as large as the vocabulary. It is also not a very natural assumption, since Skipgram is interesting to us precisely because it captures word analogies in word vector arithmetic, which are linear dependencies between the word vectors! This is not a deal breaker, however, since these linear dependencies are only ever approximate.
In order to see where the assumption arises, first recall some notation of the paper:
The authors consider the case where the negative samples for Skipgram are drawn from the uniform distribution $P_D$ over the contexts $V_C$, and write
for the log likelihood. The log likelihood is then rewritten as another double summation, in which each summand (as a function of the model parameters) depends only upon the dot product of one word vector with one context vector:
The authors then suppose that the values of the parameters $W, C$ are such that Skipgram is at equilibrium, i.e. that the partial derivatives of $l$ with respect to each word- and content-vector component vanish. They then assume that this implies that the partial derivatives of $l$ with respect to the dot products vanish also. To see that this doesn’t necessarily follow, apply the chain rule to the partial derivatives:
This yields systems of linear equations relating the partial derivatives with respect to the word- and content- vector components (which are zero by supposition) to the partial derivatives with respect to the dot products, which we want to show are zero. But this only follows if one of the two systems of linear equations has a unique solution, which is precisely when its matrix of coefficients (which are just word- or context- vector components) has linearly independent rows or columns. So either the family of word vectors or the family of context vectors must be linearly independent in order for the authors to proceed to their conclusion.
Word vectors that are of dimension the size of the vocabulary and linearly independent sound to me more akin to a one-hot or bag of words representations than to Skipgram word vectors.
Skipgram isn’t Matrix Factorisation (yet)
If Skipgram is matrix factorisation, then it isn’t shown in this paper. What has been shown is that the optima of the two methods coincide when the dimension is larger that the size of the vocabulary. Unfortunately, this tells us nothing about the lower dimensional case where Skipgram is actually interesting. In the lower dimensional case, the argument of the authors can’t be applied, since it is then impossible for the word- or context- vectors to be linearly independent. It is only in the lower dimensional case that the Skipgram and Matrix Factorisation are forced to compress the word co-occurrence information and thereby learn anything at all. This compression is necessarily lossy (since there are insufficient parameters) and there is nothing in the paper to suggest that the two methods will retain the same information (which is what it means to say that the two methods are the same).
Appendix: Comparing the objectives
To compare Skipgram with negative sampling to MF, we might compare the two objective functions. Skipgram maximises the log likelihood $l$ (above). MF, on the other hand, typically minimises the squared error between the matrix and its reconstruction:
The partial derivatives of $E$, needed for a gradient update, are easy to compute:
Compare these with the partial derivatives of the Skipgram log-likehood $l$, which can be computed as follows:
The softmax function provides a convenient parameterisation of the probability distributions over a fixed number of outcomes. Using the softmax, such probability distributions can be learned parametrically using gradient methods to minimise the cross-entropy (or equivalently, the Kullback-Leibler divergence) to observed distributions. This is equivalent to maximum likelihood learning when the distributions to be learned are one-hot (i.e. we are learning for a classification task). In the notes below, the softmax parameterisation and the gradient updates with respect to the cross entropy are derived explicitly.
This material spells out section 4 of the paper of Bridle referenced below, where the softmax was first proposed as an activation function for a neural network. It was in this paper that softmax was named, moreover. The name contrasts the outputs of the function with those of the “winner-takes-all” function, whose outputs are one-hot distributions.
The authors present a modification of the Bayesian Pairwise Ranking (BPR) for implicit feedback (i.e. one class) recommendation datasets in which the negative samples are drawn according both to the models current belief and the user/context in question (“adaptive oversampling“). They show that the prediction accuracy of BPR models trained with adaptive oversampling matches that of BPR models trained with uniform sampling but that convergence is 10x-20x faster.
Consider the problem of recommending items to users (or more generally: contexts, e.g. user on a particular page). The observed data consists then of context-item pairs $(c, i)$, where item $i$ was the choice made in context $c$. The authors work in the context of pairwise learning, which amounts to a binary classification task where context-item-item triples $(c, i, j)$ are labelled as true i.f.f. item $i$ was chosen in context $c$ but item $j$ is not:
where $\hat{y}$ is a scoring function (e.g. the dot product of the context- and the item- latent vectors, for matrix factorisation). It is infeasible to consider all the negative examples $j$, so how should we choose which to consider?
Negative sampling from static distributions
We could draw negative examples from the uniform distribution over all items, or instead from the observed distribution over all items (i.e. by popularity). Both are inexpensive to perform and easy to implement. However:
Uniform sampling tends to yield uninformative samples, i.e. those for which the probability of being incorrectly labelled is very likely already low: popular items are precisely those that appear often as positive examples (and hence tend to be highly ranked by the model), while a uniformly-drawn item is likely to be from the tail of the popularity distribution (so likely lowly ranked by the model).
Sampling according to popularity is demonstrated by the authors to converge to inferior solutions.
The authors point out that these sampling schemes depend neither upon the current context (user) nor the current belief of the model. This contrasts with their own method, adaptive over-sampling.
Adaptive over-sampling
The authors propose a scheme in which the negative samples chosen are those that the model would be likely to recommend to the user in question, according to its current state. In this sense it is reminiscent of the Gibbs sampling used by restricted Boltzmann machines.
Choosing negative samples dependent on the current model and user is computationally expensive if performed in the naive manner. The authors speed this up by working with the latent factors individually, and only periodically re-computing the ranking of the items according to each latent factor. Specifically, in the case of matrix factorisation, when looking for negative samples for a context $c$, a negative sample is chosen by:
sampling a latent factor $l$ according to the absolute values of the latent vector associated to $c$ (normalised, so it looks like a probability distribution);
sampling an item $j$ that ranks highly for $l$. More precisely, sample a rank $r$ from a geometric distribution over possible ranks, then find the item that has rank $r$ when the $l$th coordinates of the item latent vectors are compared.
(We have ignored the sign of the latent factor. If the sign is negative, one choses the rth-to-last ranked item). The ranking of the items according to each latent factor is precomputed periodically with a period such that the extra overhead is independent of the number of items (i.e. is a constant).
Problems with the approach
The samples yielded by the adaptive oversampling approach depend heavily upon the choice of basis for the latent space. It is easy to construct examples of where things go wrong:
Non-negativity constraints would solve this. Regularisation would also deal with this particular example – however regularisation would complicate the expression of the scoring function $\hat y$ as a mixture (since you need to divide though by $Z_c$.
Despite these problems, the authors demonstrate impressive performance, as we’ll see below.
Performance
The authors demonstrate that their method does converge to solutions slightly better than those given by uniform sampling, but twenty times faster. It is also interesting to note that uniform sampling is vastly superior to popularity based sampling, as shown in the diagrams below.
Note that a single epoch of the adaptive oversampling takes approximately 33% longer than a single epoch of uniform sampling BPR.
Implementation
According to the paper, the method is implemented in libFM, a C++ software package that Rendle has published. However, while I haven’t looked exhaustively, I can’t see anything in that package about the adaptive oversampling (nor in Rendle’s other package, MyMediaLite).
What about adaptive oversampling in word2vec?
Word2vec with negative sampling learns a word embedding via binary classification task, specifically, “does the word appear in the same window as the context, or not?”. As in the case of implicit feedback recommendation, the observed data for word2vec is one-class (just a sequence of words). Interestingly, word2vec samples from a modification of the observed word frequency distribution (i.e. of the “distribution according to popularity”) in which the frequencies are raised to the $0.75$th power and renormalised. The exponent was chosen empirically. This raises two questions:
Would word2vec perform better with adaptive oversampling?
How does BPR perform when sampling from a similarly-modified item popularity distribution (i.e. raising to some exponent)?
Corrections
Corrections and comments are most welcome. Please get in touch either via the comments below or via email.
We consider the “Weighted Approximate-Rank Pairwise-” (WARP-) loss, as introduced in the WSABIE paper of Weston et. al (2011, see references), in the context of making recommendations using implicit feedback data, where it has been shown several times to perform excellently. For the sake of discussion, consider the problem of recommending items $i$ to users $u$, where a scoring function $f_u(i)$ gives the score of item $i$ for user $u$, and the item with the highest score is recommended.
WARP considers each observed user-item interaction $(u, i)$ in turn, choses another “negative” item $i’$ that the model believed was more appropriate to the user, and performs gradient updates to the model parameters associated to $u$, $i$ and $i’$ such that the models beliefs are corrected. WARP weights the gradient updates using (a function of) the estimated rank of item $i$ for user $u$. Thus the updates are amplified if the model did not believe that the interaction $(u, i)$ could ever occur, and are dampened if, on the other hand, if the interaction is not surprising to the model. Conveniently, the rank of $i$ for $u$ can be estimated by counting the number of sample items $i’$ that had to be considered before one was found that the model (erroneously) believed more appropriate for user $u$.
Minimising the rank?
Ideally we would like to make updates to the model parameters that minimised the rank of item $i$ for user $u$. Previous work of Usunier (one of the authors) showed that the precision at k was best optimised when the logarithm of the rank was minimised. (to read!)
The problem with the rank is that, while it does depend on the model parameters, this dependence is not continuous (the rank being integer valued!). So it is not possible to speak of gradients. So what is to be done instead? The approach of the authors is to derive a differentiable approximation to the logarithm of the rank, and to minimise this instead.
Derivation: approximating the (log of the) rank
WARP has been shown several times to perform very well for implicit feedback recommendation. However, the derivation of the approximation of the log of the rank used in WARP, as outlined in the WSABIE paper, is nonsense. I can only think that the authors arrived at WARP in another way. Let’s look at it more closely. In the following:
$f_u (i)$ is the score assigned by the model to item $i$ for user $u$.
$L$ is some function that defines the error as a function of the rank. In the WSABIE paper, $L(k) = \sum_{j=1}^k \frac{1}{j}$ is approximately the natural logarithm (for the derivation below, however, it doesn’t matter what $L$ is)
The most obvious problem with the derivation is the approximation marked with an asterix (*). At this step, the authors approximate the indication function $I[x > y]$ by $I[x > y] \cdot (x – y + 1)$. While the latter is familiar as the hinge loss from SVMs, it is (begin unbounded!) a dreadful approximation for the indicator $I[x > y]$. It seems to me that the sigmoid of the difference of the scores would be a much better differentiable approximation to the indicator function.
To appreciate why the derivation is nonsense, however, you have to notice that the it has nothing to do with $L$. That is, the derivation above would yield an approximation for $L$, whatever $L$ happened to be, even a constant function.
Optimisation
WARP considers each observed interaction $(u, i)$ in turn, repeatedly sampling items $i’$ from the uniform distribution over all items until it finds one in $V_{u, i}^1$, i.e. until it finds an item $i’$ whose score for the user $u$ is at worst 1 less than the score of the observed interaction. For this triple $(u, i, i’)$, it performs gradient updates to minimise:
The naive approach to computing $\text{rank}_u^1 (i)$ is to calculate all the scores for the given user in order to determine the rank of the item $i$. WARP performs a nice trick to do much better: it estimates $\text{rank}_u^1 (i)$ by counting how many candidate negative items $i’$ it had to consider before finding one in $V_{u, i}^1$. This yields
$\displaystyle \text{rank}_u^1 (i) \approx \frac{\text{total number of items} – 1}{\text{number of i’ we had to draw}}$
However it is still the case that $L(\text{rank}_u^1 (i))$ is not differentiable. So when we compute the gradients, this quantity has to be treated as a constant. Thus it simply becomes a weighting applied to the gradient of the difference of the scores (hence the name WARP, I guess).
WARP optimises for item to user recommendations
With its negative sampling technique, WARP optimises for recommending items to a user. For instance, the problem of recommending users to items (so, transposing the interaction matrix) is not trained for. I wonder if some extra uplift could be obtained by training for both problems simultaneously.
Normalising for the total number of items
With the optimisation stated as above, the learning rate will need to be re-tuned for datasets that have different numbers of items, since the gradient weighting $L( \text{rank}_u^1 (i) )$ is ranges from $L(0)$ to $L(\text{total number items})$. It would make more sense to weigh the gradient updates by:
$\displaystyle \frac{L( \text{rank}_u^1 (i) )}{L(\text{total number items})}$
which ranges between 0 and 1.
Implementations
There are two implementations of WARP for recommendation that I know of, both in Python:
LightFM, written by Maciej Kula. Works well. Also implements BPR with uniform sampling and WARP k-OS (which I’ve not investigated yet).
MREC, written by Levy and Jack at Mendeley, has a matrix factorisation recommender trained using WARP. I’ve not tried this one out yet.
References
Jason Weston, Samy Bengio and Nicolas Usunier, Wsabie: Scaling Up To Large Vocabulary Image Annotation, 2011, (PDF).
Below are the notes I made to prepare for a short talk given at our seminar on learning distance metrics, and the Mahalanobis distances in particular. We show that the Mahalanobis distances can be parameterised by the positive semidefinite (PSD) matrices or alternatively (in a highly redundant way) by all matrices. The set of PSD matrices is convex, but in order to perform gradient descent to optimise the objective function, we need to perform a costly projection after each update involving the singular value decomposition.
We note along the way that a Mahalanobis distance is nothing more than the Euclidean distance after applying a linear transform to the data.
The example of the 2×2 PSD matrices is worked out in detail here.
What’s here documents my first steps. What I really discovered is that metric learning is a research domain in its own right, and that a great deal of work has been done. There is an excellent survey by Bellet et al. (2013) that covers everything I have said in the first two of its sixty pages.
Recall that a symmetric matrix $M \in \mathbb{R}^{n \times n}$ is called positive semidefinite (“PSD”) if, for any $x \in \mathbb{R}^n$, we have $x^{T} M x \geqslant 0$. Positive semidefinite matrices occur, for instance, in the study of bilinear forms and as the Gram (or covariance) matrices in probability theory. In the case where $n = 2$, the space of symmetric matrices is 3-dimensional, and we can actually draw the subset of all positive semidefinite matrices – it looks like the bow of a ship.
It is clear that in the case illustrated below, the PSD matrices form a convex subset. It is easy to show this in general, by observing that the set of all PSD matrices is closed under addition and multiplication by non-negative scalars. The convexity of this set is crucial for the fitting of Mahalanobis distances in metric learning, which is how I got interested PSD matrices in the first place.
In a paper with Adriaan Schakel, we presented controlled experiments for word embeddings using pseudo-words. Performing these experiments in the case of word2vec CBOW showed that, in particular, the vector direction of any particular word changed only moderately when the frequency of the word was varied. Shortly before we released the paper, Schnabel et al presented an interesting paper at EMNLP, where (amongst other things), they showed that it was possible to distinguish rare from frequent words using logistic regression on the normalised word vectors, i.e. they showed that vector direction does approximately encode coarse (i.e. binary, rare vs. frequent) frequency information. Here, I wanted to quickly report that the result of Schnabel et al. holds for the vectors obtained from our experiments, as they should. Below, I’ll walk through exactly what I checked.
I took the word vectors that we trained during our experiments. You can check our paper for a detailed account. In brief, we trained a word2vec CBOW model on popular Wikipedia pages with a hidden layer of size 100, negative sampling with 5 negative samples, a window size of 10, a minimum frequency of 128, and 10 passes through the corpus. Sub-sampling was not used so that the influence of word frequency could be more clearly discerned. There were 81k unigrams in the vocabulary. Then:
the word vectors were normalised so that their (Euclidean-) length was 1.
the frequency threshold of 5000 was chosen (somewhat arbitrarily) to define the boundary between rare and frequent words. This gave 8428 “frequent” words. A random sample of the same size of the remaining “rare” words was then chosen, so that the two classes, “rare” and “frequent”, were balanced. This yielded approximately 17k data points, where a data point is a normalised word vector labelled with either “frequent” (1) or “rare” (0).
the data points were split into training- and test- sets, with 70% of the data points in the training set.
a logistic regression model was fit on the training set. An intercept was fit, but this boosted the performance only slightly. No regularisation was used since the number of training examples wass high compared to the number of parameters.
The performance on the test set was assessed by calculating the ROC curve on the training and test sets and the accuracy on the test set.
Model performance
Consider the ROC curve below. We see from that fact that the test curve approximately tracks the training curve that the model generalises reasonably to unseen data. We see also from the closeness of the curves to the axes at the beginning and the end that the model is very accurate in detecting frequent words when it gives a high probability (bottom left of the curve) and at detecting infrequent words when it gives a low probability (top right).
The accuracy of the model on the test set was 82%, which agrees very nicely with what was reported in Schnabel et al., summarised in the following image:
The training corpus and parameters of Schnabel, though not reported in full detail (they had a lot of other things to report), seem similar. We know that their CBOW model was 50 dimensional, had a vocabulary of 103k words, and was trained on the 2008 Wikipedia.
Below are the notes I prepared for a talk that I gave at our seminar on limiting distributions for (finite-state, time-homogeneous) Markov chains, drawing on PageRank as an example. We see in particular how the “random teleport” possibility in the PageRank random walk algorithm can be motivated by the theoretical guarantees that result from it: the transition matrix is both irreducible and aperiodic, and iterated application of the transmission matrix converges more rapidly to the unique stationary distribution.
Update: that the limit of the average time spent is the reciprocal of the expected return time can be proved using the renewal reward theorem (thank you Prof. Sigman!)
GloVe trains word embeddings by performing a weighted factorisation of the log of the word co-occurrence matrix. The model scales to very large corpora (Common Crawl 840B tokens) and performs well on word analogy tasks.
$X$ denotes the word co-occurrence matrix (so $X_{i,j}$ is the number of times that word $j$ occurs in the context of word $i$)
the weighting $f$ is given by $f(x) = (x / x_{\text{max}})^\alpha$ if $x < x_{\text{max}}$ and $1$ otherwise,
$x_{\text{max}} = 100$ and $\alpha = 0.75$ (determined empirically),
$u_i, v_j$ are the two layers of word vectors,
$b_i, c_j$ are bias terms.
Note that the product is only over pairs $i, j$ for which $X_{i,j}$ is non-zero. This means that GloVe (in contrast to word2vec with negative sampling) trains only “positive samples” and also that we don’t have to worry about the logarithm of zero.
This is essentially just weighted matrix factorisation with bias terms:
Note that in the implementation (see below), the $X_{i,j}$ are not raw co-occurrence counts, but rather the accumulated inverse distance between the two words, i.e.
I am fairly sure that the implementation of Adagrad is incorrect. See my post to the forum.
The factor weighting f
The authors go to some trouble to motivate the definition of this cost function (section 3). The authors note that many different functions could be used in place of their particular choice of $f$, and further that their $\alpha$ coincides with that used by word2vec for negative sampling. I can’t see the relevance of the latter, however (in word2vec, the $0.75$th power it is used to define the noise distribution; moreover powering a value in the range $[0, 1]$ has a very different effect to powering a value in the range $[0, 100]$).
Graphing the function (see above) hints that it might have been specified more simply, since the non-linear region is in fact almost linear.
A radial window size of 10 is used. Adagrad is used for optimisation.
Word vectors The resulting word embeddings ($u_i$ and $v_j$) are unified via a direct sum of their vector spaces.
The cosine similarity is used to find the missing word in word similarity tasks. It is not stated if the word vectors were normalised before forming the arithmetic combination of word vectors.
Source code The authors take the exemplary step of making the source code available.
Evaluation and comparison with word2vec The authors do a good job of demonstrating their approach, but do a scandalously bad job of comparing their approach to word2vec. This seems to reflect a profound misunderstanding on the part of the authors as to how word2vec works. While it has to be admitted that the word2vec papers were not well written, it is apparent that the authors made very little effort at all.
The greatest injustice is the comparison of the performance of GloVe with an increasing number of iterations to word2vec with an increasing number of negative samples:
The most important remaining variable to control for is training time. For GloVe, the relevant parameter is the number of training iterations. For word2vec, the obvious choice would be the number of training epochs. Unfortunately, the code is currently designed for only a single epoch: it specifies a learning schedule specific to a single pass through the data, making a modification for multiple passes a non-trivial task. Another choice is to vary the number of negative samples. Adding negative samples effectively increases the number of training words seen by the model, so in some ways it is analogous to extra epochs.
Firstly, it is simply impossible that it didn’t occur to the authors to simulate extra iterations through the training corpus for word2vec by simply concatenating the training corpus with itself multiple times. Moreover, the authors themselves are capable programmers (as demonstrated by their own implementation). The modification to word2vec that they avoided is the work of ten minutes.
Secondly, the notion that increasing the exposure of word2vec to noise is comparable to increasing the exposure of GloVe to training data is ridiculous. The authors clearly didn’t take the time to understand the model they were at pains to criticise.
While some objections were raised about the evaluation performed in this article and subsequent revisions have been made, the GloVe iterations vs word2vec negative sample counts evaluation persists in the current version of the paper.
Another problem with the evaluation is that the GloVe word vectors formed as the direct sum of the word vectors resulting from each matrix factor. The authors do not do word2vec the favour of also direct summing the word vectors from the first and second layers.
Links
Radim’s blog post includes an independent comparison of word2vec and GloVe performance;
We show below that vectors drawn uniformly at random from the unit sphere are more likely to be orthogonal in higher dimensions.
In information retrieval and other areas besides, it is common to use the dot product of normalised vectors as a measure of their similarity. It can be problematic that the similarity measure depends upon the rank of the representation, as it does here — it means, for example, that similarity thresholds (for relevance in a particular situation) need to be re-calibrated if the underlying vectorisation model is retrained e.g. in a higher dimension.
Question
Does anyone have a solution to this? Is there a (of course, dimension dependent) transformation that can be applied to the dot product values to arrive at some dimension independent measure of similarity?
I asked this question on “Cross Validated”. Unfortunately, it has attracted so little interest that it has earned me the “tumbleweed” badge!
For those interested in the distribution of the dot products, and not just the expectation and the variance derived below, see this answer by whuber on Cross Validated.
This is the standard, elementary arithmetic proof that the marginal and conditional distributions of the multivariate Gaussian are again Gaussian with parameters expressible in terms of the covariance matrix of the original Gaussian. We use the block multiplication of matrices.
I was surprised by how much work is required to show this, and feel moreover that the proof (while correct) fails to offer any intuitive understanding. Is there not a higher-level, co-ordinate free proof of this important result, perhaps one that uses characteristic properties of multivariate Gaussians?
Update: I received an answer to this question on Cross Validated from whuber. He uses a generative definition: the multivariate Gaussians are precisely the affine transformations of tuples of standard (mean zero, unit-variance) one-dimensional Gaussians. Using this definition, it follows quickly that the conditional and marginal distributions must be multivariate Gaussian.
Consider a matrix product $AB$. Partition the two outer dimensions (i.e. the rows of $A$ and the columns of $B$) and the one inner dimension (i.e. the columns of $A$ and the rows of $B$) arbitrarily. This defines a “block decomposition” of the product $AB$ and of the factors $A, B$ such that the blocks of $AB$ are related to the blocks of $A$ and $B$ via the familiar formula for components of the product, i.e.
$(AB)_{m,n} = \sum_s A_{m,s} B_{s,n}$.
Pictorially, we have the following:
Arithmetically, this is easy to prove by considering the formula above for the components of the product. The partitioning of the outer dimensions comes for free, while the partitioning of the inner dimension just corresponds to partitioning the summation:
Zooming out to a categorical level, we can see that there is nothing peculiar about this situation. If, in an additive category, we have three objects $X, Y, Z$ with biproduct decompositions, and a chain of morphisms:
$X \xrightarrow{\varphi_B} Y \xrightarrow{\varphi_A} Z$
then this “block decomposition of matrices” finds expression as a formula in $\text{End}(X, Z)$ using the injection and projection morphisms associated with each biproduct factor.
Presented at NIPS 2014 (PDF) by Dai, Olah, Le and Corrado.
Model
The authors consider a modified version of the PV-DBOW paragraph vector model. In previous work, PV-DBOW had distinguished words appearing in the context window from non-appearing words given only the paragraph vector as input. In this modified version, the word vectors and the paragraph vectors take turns playing the role of the input, and word vectors and paragraph vectors are trained together. That is, a gradient update is performed for the paragraph vector in the manner of regular PV-DBOW, then a gradient update is made to the word vectors in the manner of Skipgram, and so on. This is unfortunately less than clear from the paper. The authors were good enough to confirm this via correspondence, however (thanks to Adriaan Schakel for communicating this). For the purposes of the paper, this is the paragraph vector model.
The representations obtained from paragraph vector (using cosine similarity) are compared to those obtained using:
an average of word embeddings
LDA, using Hellinger distance (which is proportional to the L2 distance between the component-wise square roots)
paragraph vector with static, pre-trained word vectors
In the case of the average of word embeddings, the word vectors were not normalised prior to taking the average (confirmed by correspondence).
Corpora
Two corpora are considered, the arXiv and Wikipedia:
4.5M articles from Wikipedia, with a vocabulary of size 915k
886k articles from the arXiv, full texts extracted from the PDFs, with a vocabulary of 970k words.
Only unigrams are used. The authors observed that bigrams did not improve the quality of the paragraph vectors. (p3)
Quantitative Evaluation
Performance was measured against collections of triples, where each triple consisted of a test article, an article relevant to the test article, and an article less relevant to the test article. While not explicitly stated, it is reasonable to assume that the accuracy is then taken to be the rate at which similarity according to the model coincides with relevance, i.e. the rate at which the model says that the relevant article is more similar than the less relevant article to the test article. Different sets of triples were considered, the graph below shows performance of the different methods relative to a set of 172 Wikipedia triples that the authors built by hand (these remain unreleased at the time of writing).
It is curious that, with the exception of the averaged word embeddings, the accuracy does not seem to saturate as the dimension increases for any of the methods. However, as each data point is the accuracy of a single training (confirmed by correspondence), this is likely nothing more than the variability inherent to each method. It might suggest, for example, that the paragraph vectors method has a tendency to get stuck in local minima. This instability in paragraph vector is not apparent, however, when tested on the triples that are automatically generated from Wikipedia (Figure 5). In this latter case, there are many more triples.
Performance on the arXiv is even more curious: accuracy decreases markedly as the dimension increases!
Implementations
I am not sure there are any publicly available implementations of this modified paragraph vectors method. According to Dai, the implementation of the authors uses Google proprietary code and is unlikely to be released. However it should be simple to modify the word2vec code to train the paragraph vectors, though some extra code will need to be written to infer paragraph vectors after training has finished.
I believe that the gensim implementation provides only the unmodified version of PV-DBOW, not the one considered in this paper.
Comments
It is interesting that the paragraph vector is chosen so as to best predict the constituent words, i.e. it is inferred. This is a much better approach from the point of view of word sense disambiguation than obtaining the paragraph vector as a linear image of an average of the word vectors (NMF vs PCA, in their dimension reductions on bag of words, is another example of this difference).
Thanks to Andrew Dai and Adriaan Schakel for answering questions!
Questions
Is there is an implementation available in GenSim? (see e.g. this tutorial).
(Tangent) What is the motivation (probabilistic meaning) for the Hellinger distance?
Below are notes from a talk on Expectation Maximisation I gave at our ML-learning group. Gaussian mixture models are considered as an example application.
Another useful reference is likely the 1977 paper by Dempster et al. that made the technique famous (this is something I would have liked to have read, but didn’t).
Questions
I still don’t understand how EM manages to (reportedly) work so well, given that the maximisation chooses for the next parameter vector precisely the one that reinforces the “fantasy” completions of the data made by the previous parameter vector. I would not have considered it a good learning strategy. It contrasts greatly with, for example, the learning strategy of a restricted Boltzmann machine, in which, at each iteration, the parameters are adjusted so as to correct the model’s fantasy towards producing the observed data.
Can we offer a better argument for why maximisation of the likelihood for latent variable models is difficult?
Is the likelihood of an exponential family distribution convex in the parameters? This is certainly the case for e.g. the mean of a Gaussian. Does this explain why the maximisation of the constructed lower bound for the likelihood is easy?
Here we calculate the entropy of the normal distribution and show that the normal distribution has maximal entropy amongst all distributions with a given finite variance.
The video belong concerns just the calculation of the entropy, not the maximality property.
Shannon makes this claim in his 1948 paper and lists this property as one of his justifications for the definition of entropy. We give a short proof of his claim.
Here we consider the problem of approximately factorising a matrix $X$ without constraints and show that solutions can be generated from the orthonormal eigenvectors of the Gram matrix $X^T X$ (i.e. of the sample covariance matrix).
(Speculative) can we characterise the solutions as orbits of the orthogonal group on the solutions above, and on those solutions obtained from the above by adding rows of zeros to $B$?
Under what constraints, if any, are the optimal solutions to matrix factorisation matrices with orthonormal rows/columns? To what extent does orthogonality come for free?
Below is a re-digestion of Walton’s one-pager on projected gradient descent, in which I have corrected some inconsequential mistakes of his and doubtless introduced more serious ones of my own. Corrections and suggestions welcome, as always.
Below is a (rough!) draft of a talk I gave at the Berlin Machine-Learning Learning-Group on the bias-variance trade-off, including the basics of estimator theory, some examples and maximum likelihood estimation.
We show that a real, symmetric matrix has basis of real-valued orthonormal eigenvectors and that the corresponding eigenvalues are real. We show moreover that these eigenvalues are all non-negative if and only if the matrix is positive semi-definite.
Below are the slides from my talk at the Berlin Machine Learning Meetup group on July 8, 2014, giving an overview of word2vec, covering the CBOW learning task, hierarchical softmax and negative sampling.


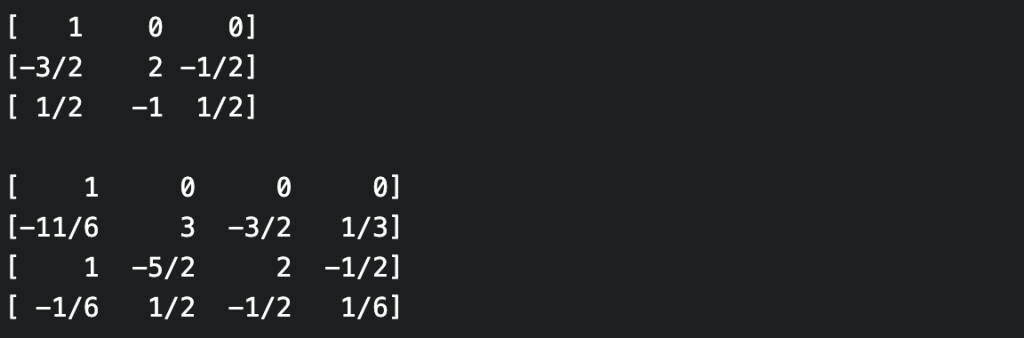
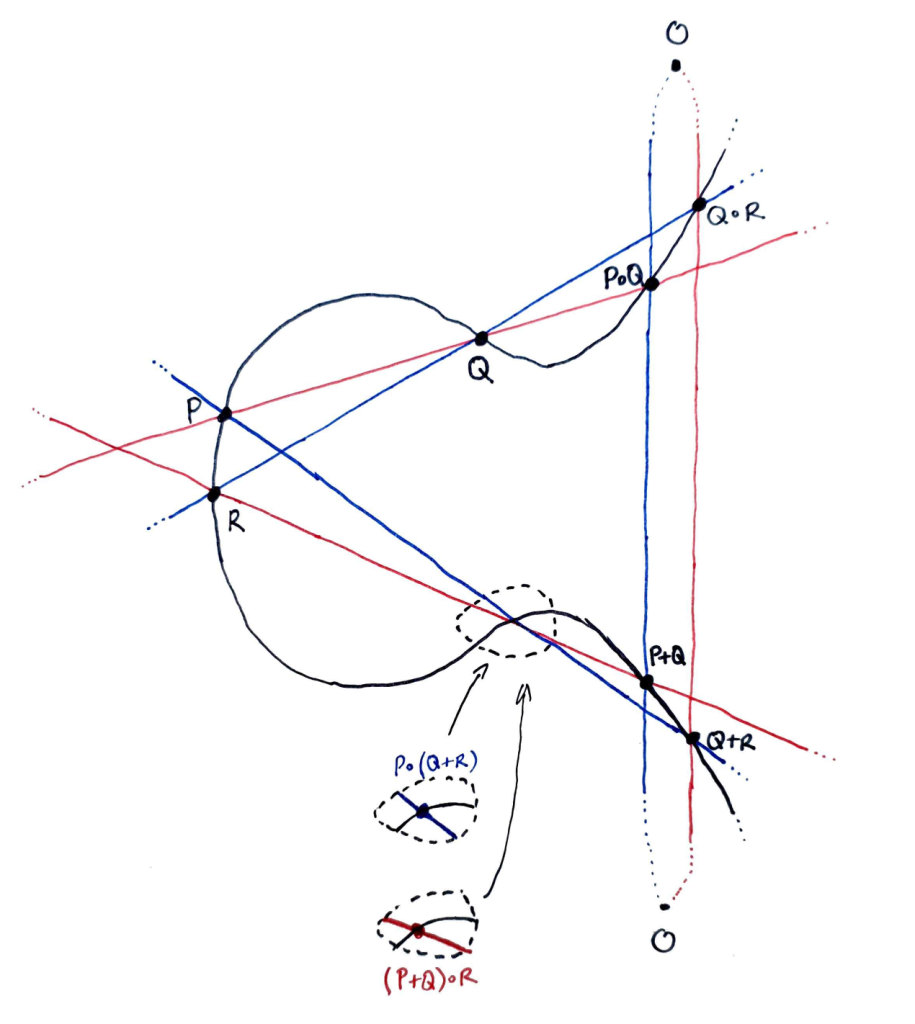
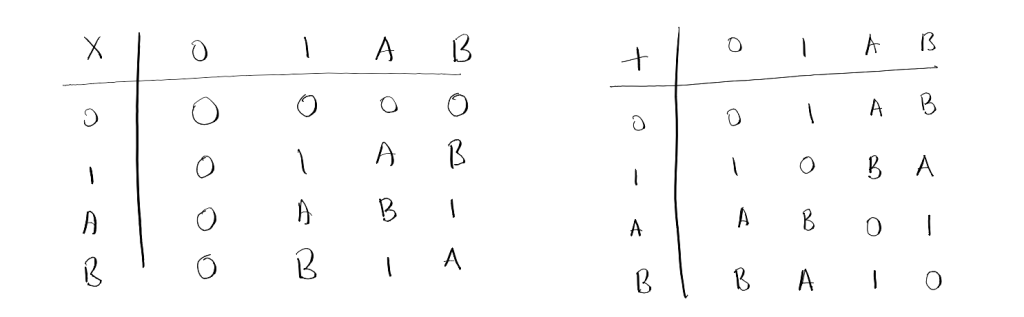
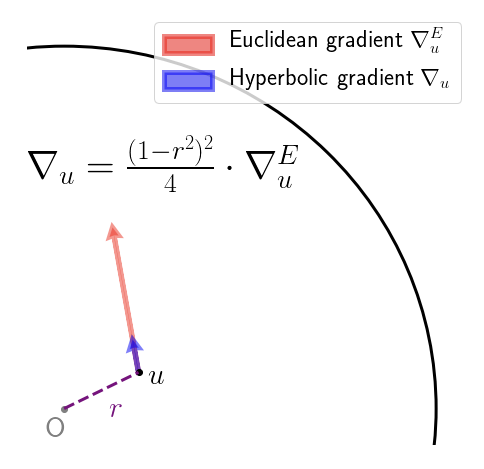
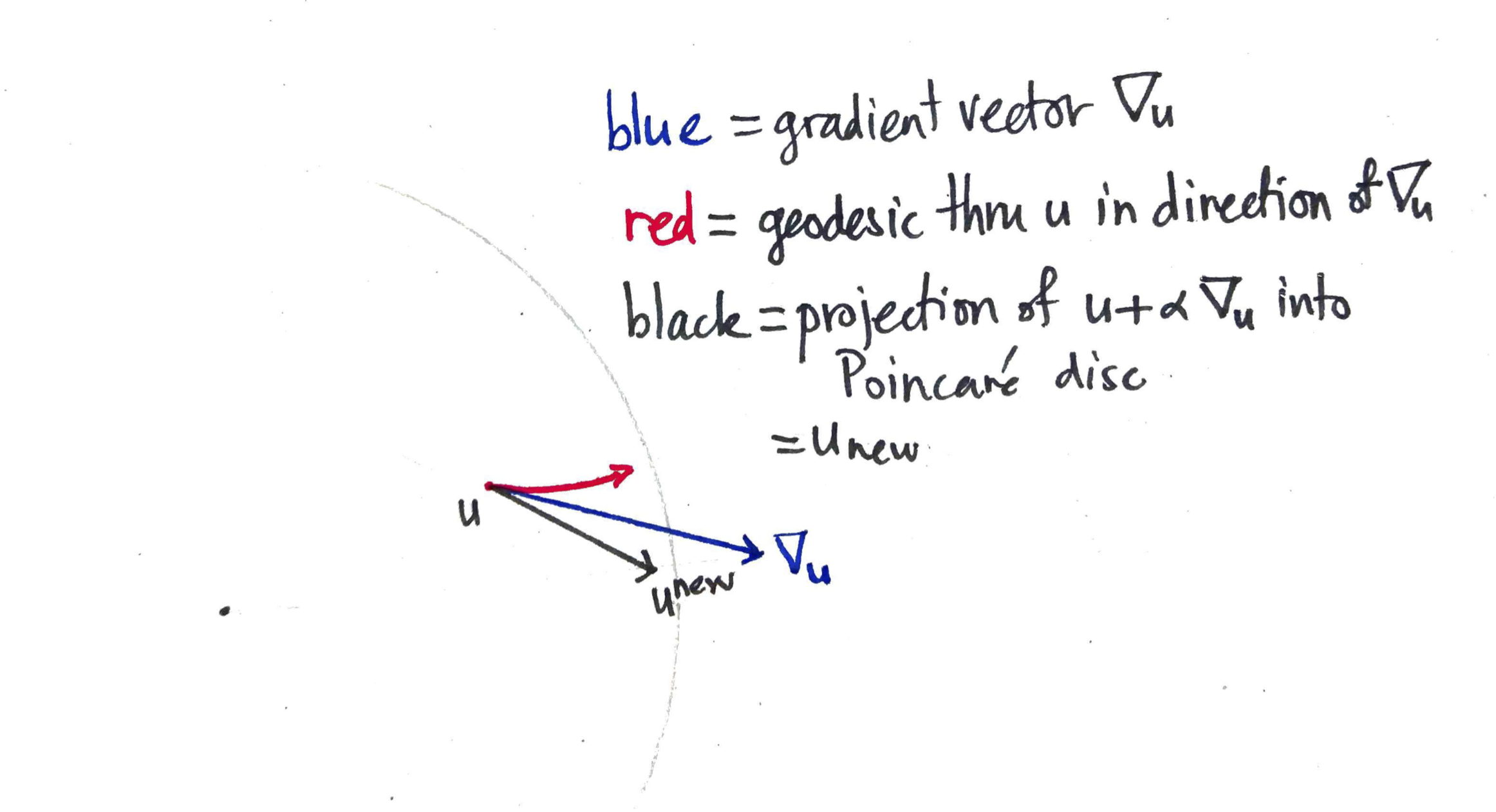


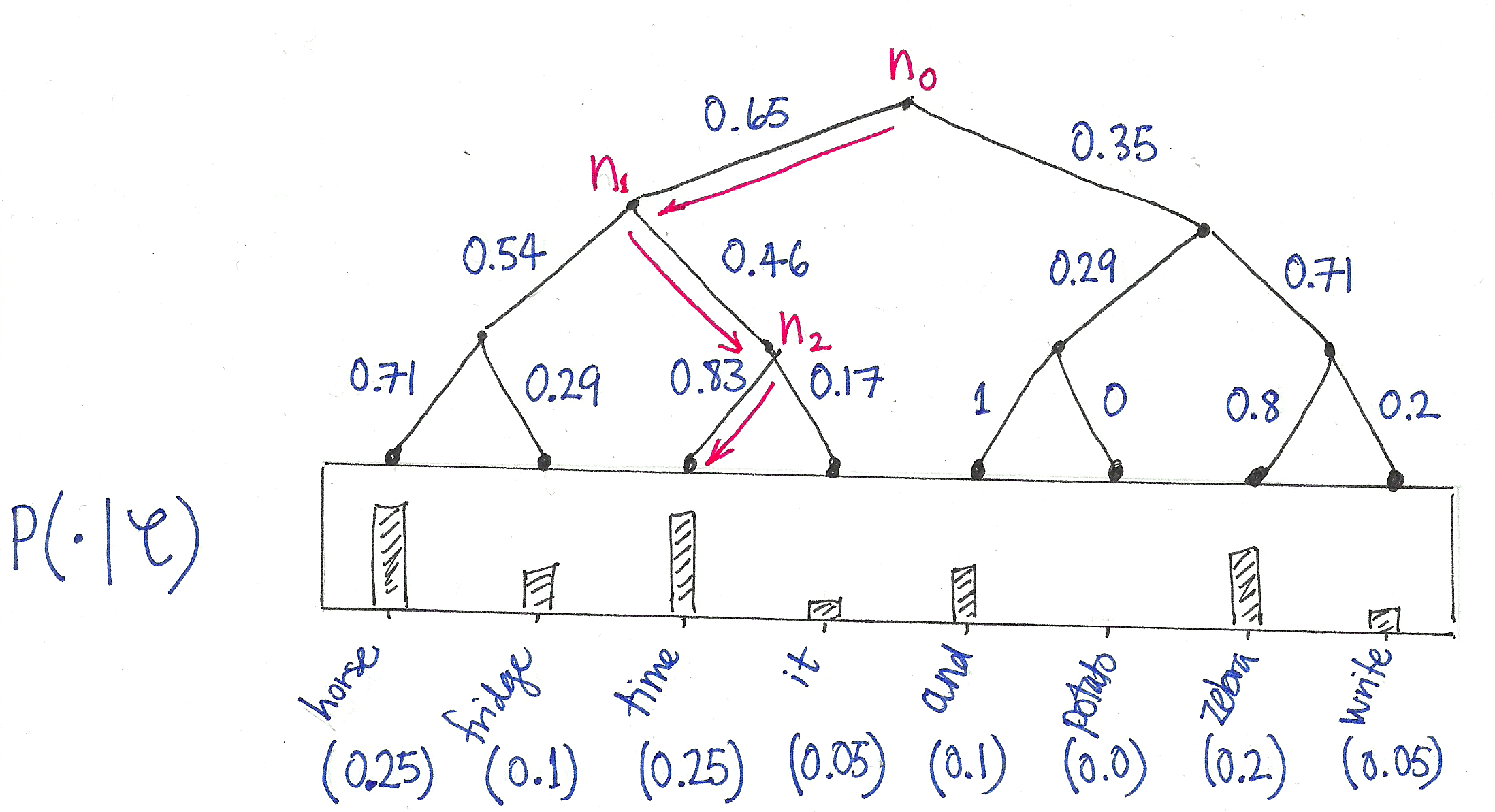
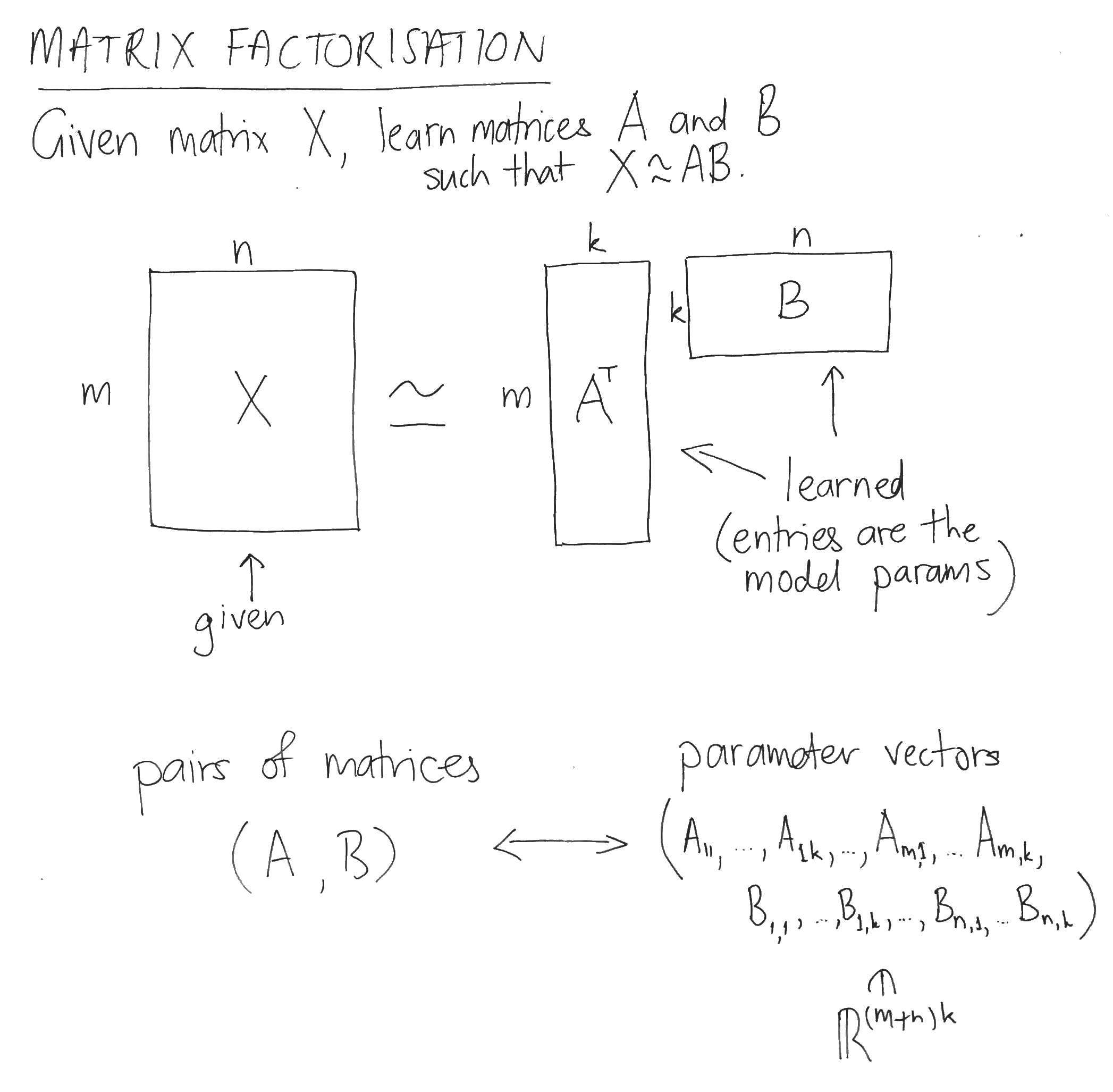
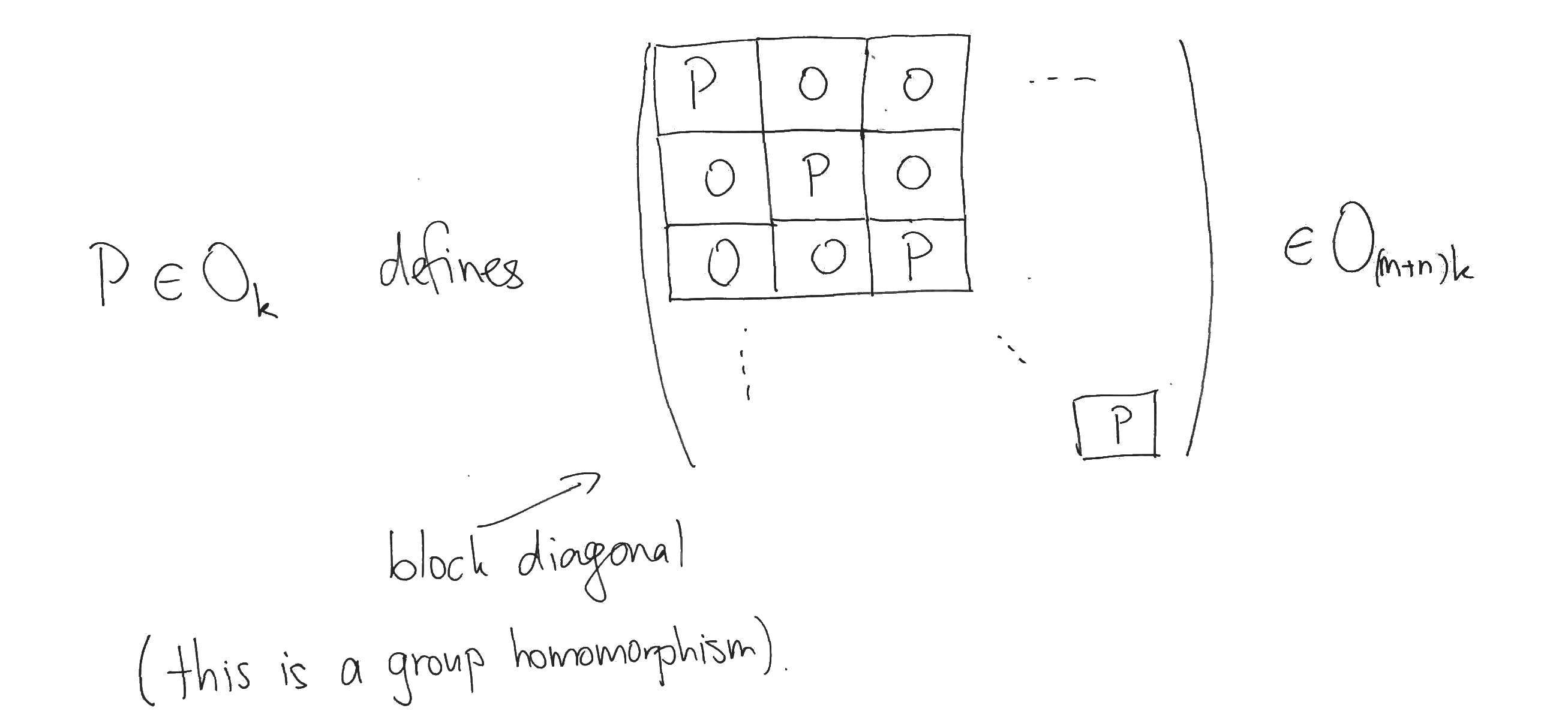

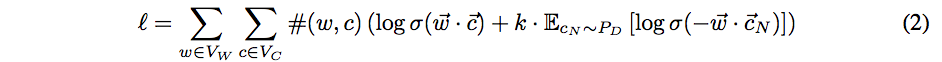
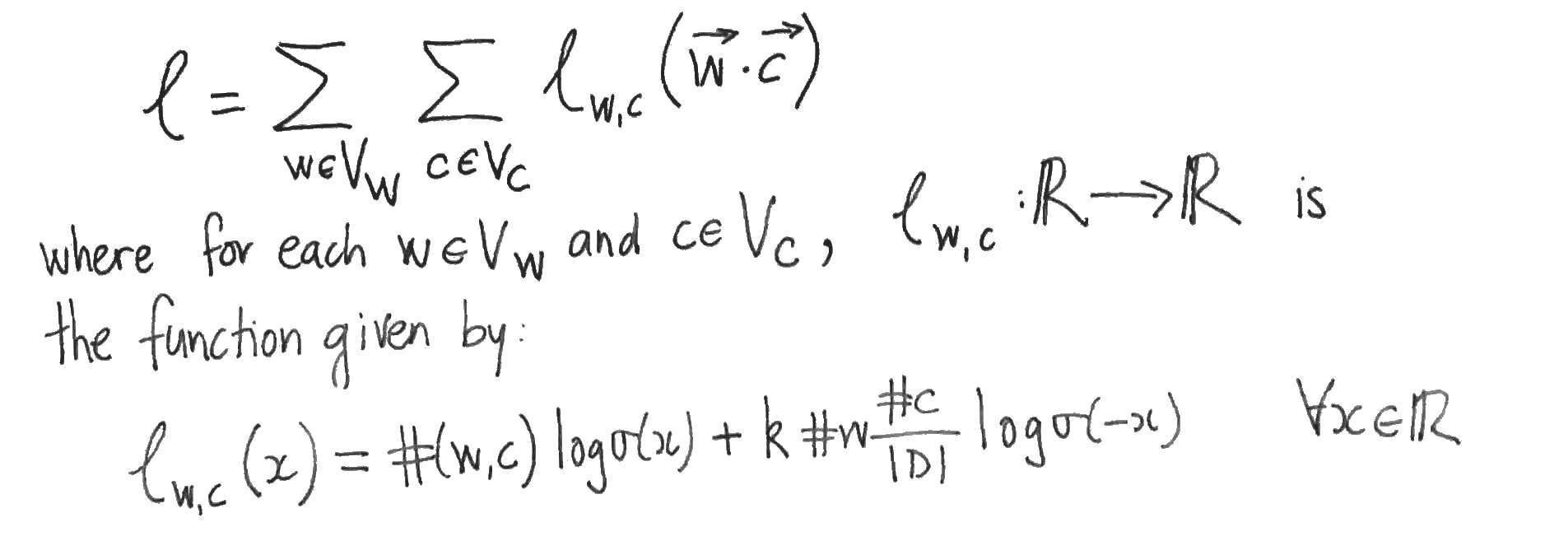
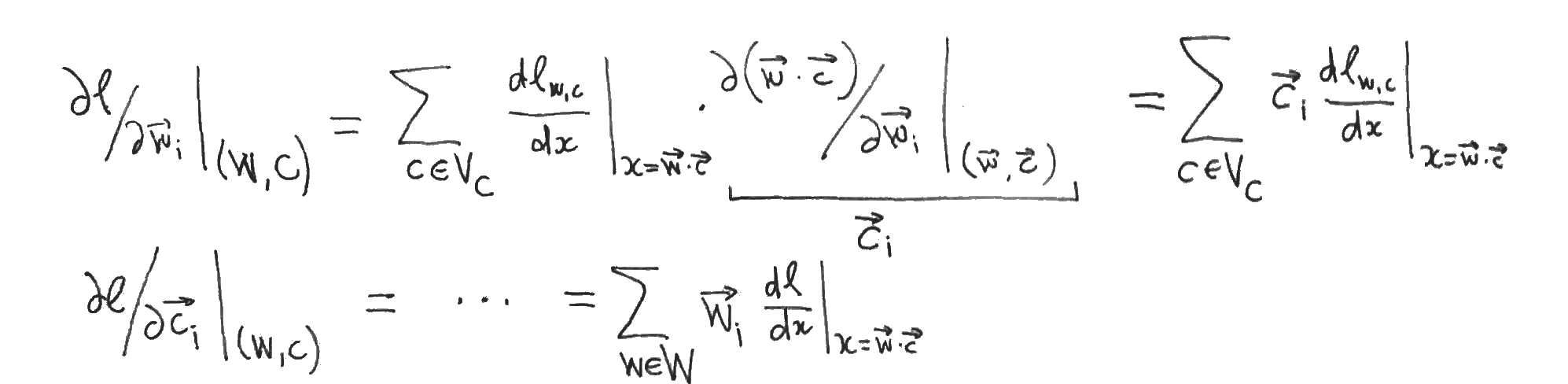
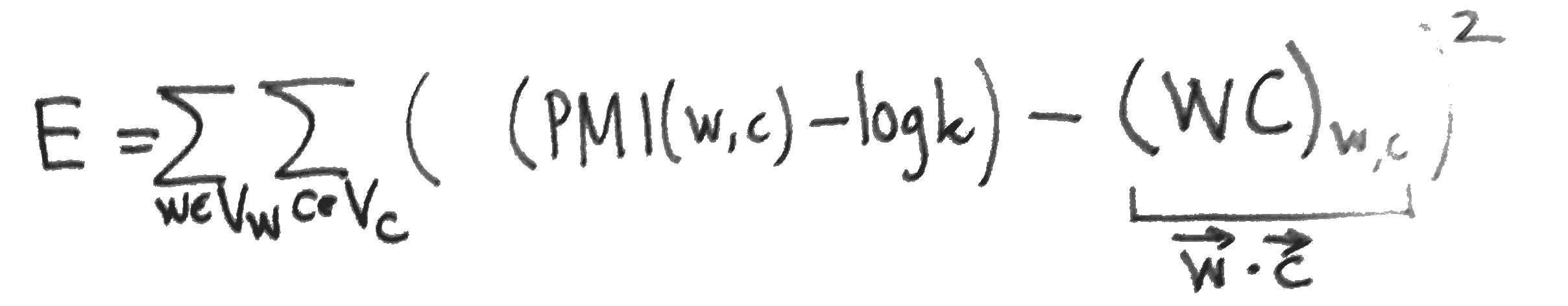
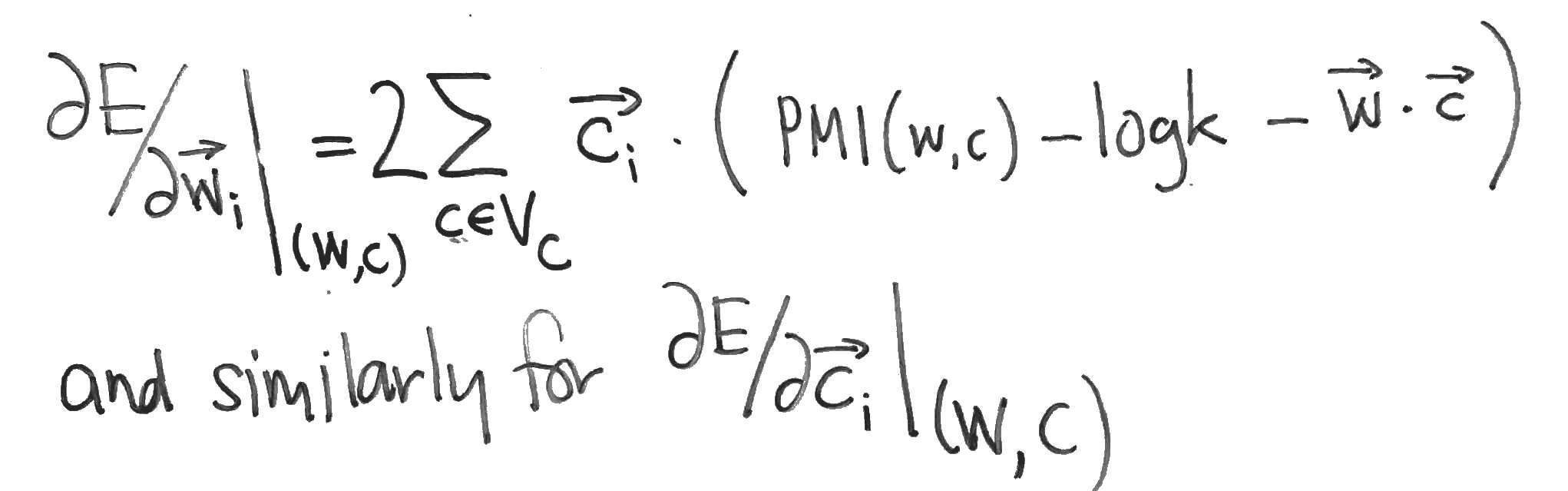
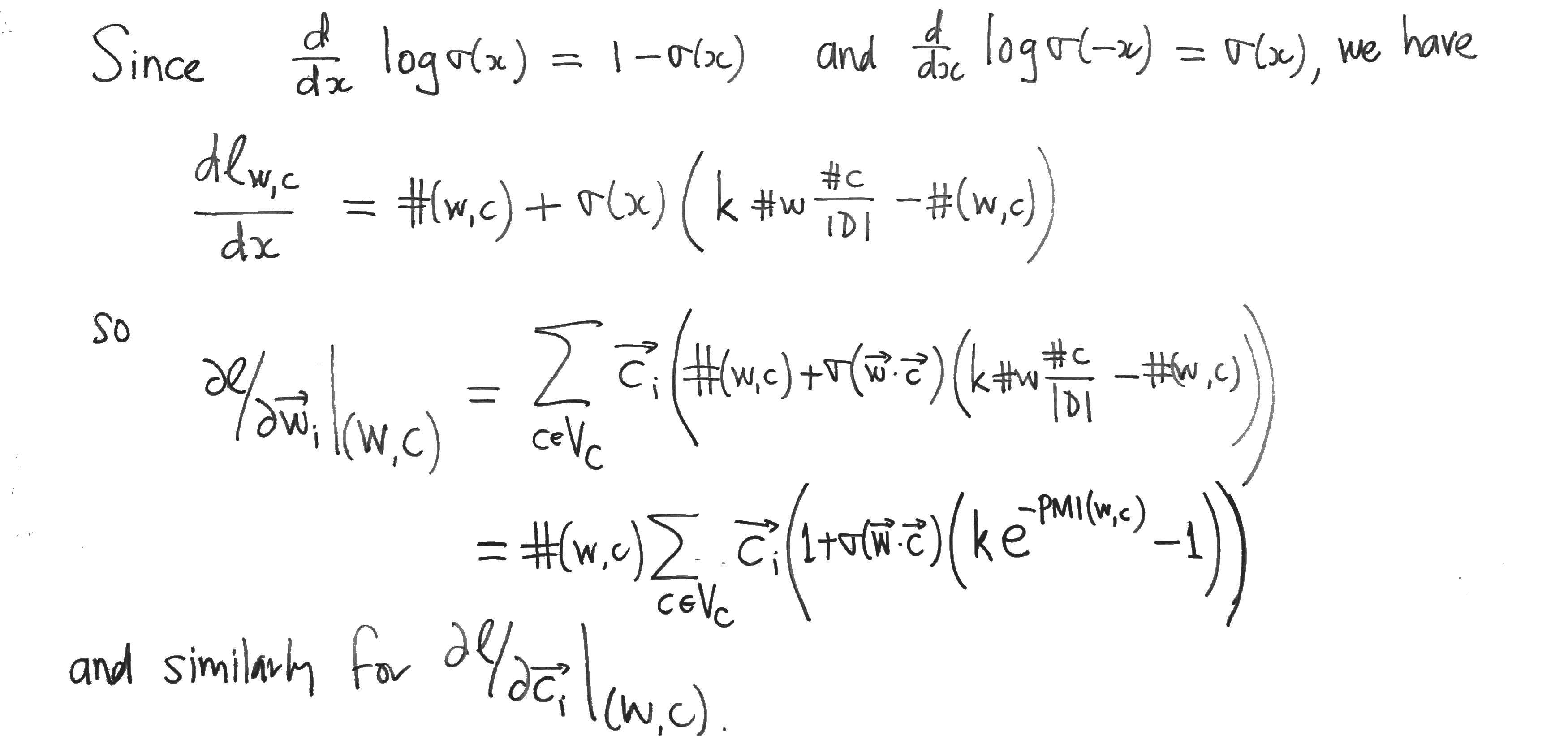
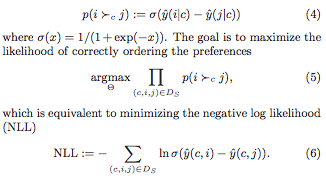
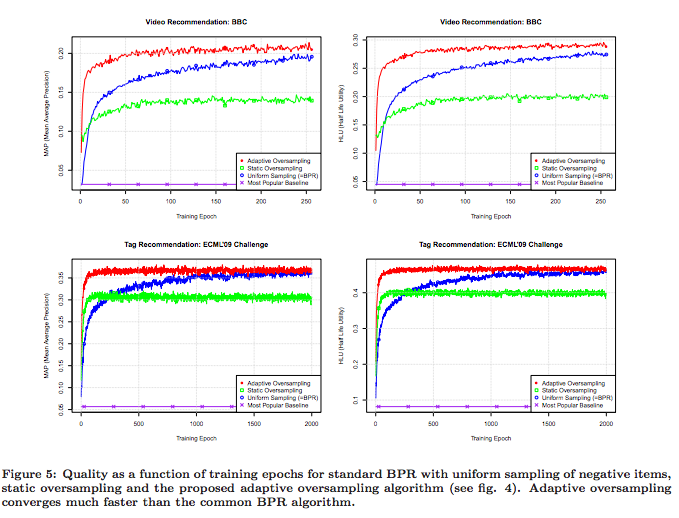
 The most obvious problem with the derivation is the approximation marked with an asterix (*). At this step, the authors approximate the indication function $I[x > y]$ by $I[x > y] \cdot (x – y + 1)$. While the latter is familiar as the hinge loss from SVMs, it is (begin unbounded!) a dreadful approximation for the indicator $I[x > y]$. It seems to me that the sigmoid of the difference of the scores would be a much better differentiable approximation to the indicator function.
The most obvious problem with the derivation is the approximation marked with an asterix (*). At this step, the authors approximate the indication function $I[x > y]$ by $I[x > y] \cdot (x – y + 1)$. While the latter is familiar as the hinge loss from SVMs, it is (begin unbounded!) a dreadful approximation for the indicator $I[x > y]$. It seems to me that the sigmoid of the difference of the scores would be a much better differentiable approximation to the indicator function.