Non-negative matrix factorisation (NMF) learns to reconstruct samples as a superposition of their constituent parts. In the paper of Lee and Seung (1999) that popularised NMF, this is called a “parts-based” representation. This is illustrated in that paper by applying NMF to encodings of images of faces, where NMF seems to decompose the faces into a collage of eigen-eyebrows and eigen-noses. Visual demonstrations are fantastic for conveying ideas, but in this particular instance, the clarity is compromised by the inherent noisiness of real-world facial images. The images are drawn, moreover, from the CBCL dataset, which has a non-commercial license. In order to get around this problem, and to have an even clearer visual demonstration of the “parts-based” decomposition provided by NMF for my course at DataCamp, I created a synthetic image dataset, where each image is of a single digit of a LCD display, as on a clock radio. The parts learned by NMF are then the individual “cells” of the LCD display.
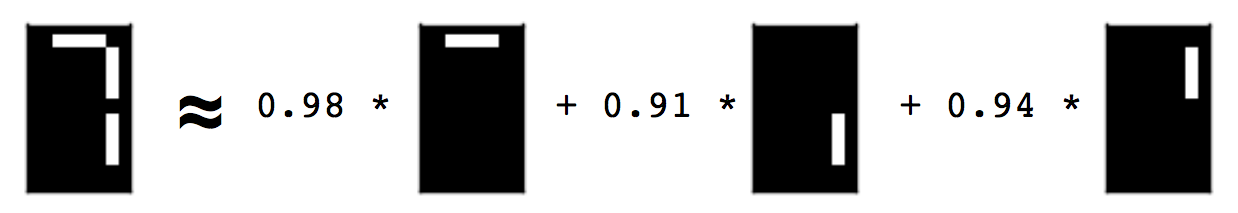
You can construct this dataset yourself, using the code below. The collection of images is encoded as a 2d array of non-negative values. Each row corresponds to an image, and each column corresponds to a pixel. The non-negative entries represent the whiteness of the pixel, encoded here as a value between 0 and 1.
Alternatives
- The standard bars provide a similar (but more apparently synthetic) image dataset for learning the parts of images. See, for example, the references given in Spratling (1996).
- Another great visual dataset could be built from black-and-white images of the 52 playing cards in a deck. NMF would then learn the ranks (i.e. ace, 2, 3, …, ) and the suits (i.e. spades, hearts, …) as parts, and reconstruct playing cards from these. I haven’t done this.
- Yet another great example dataset could be constructed using images of a piano keyboard, or perhaps just an octave range, colouring the keys according to how often they are pressed during a song. NMF should then be able to learn the chords as parts. The midi files to construct this dataset could be obtained from the Mutopia project, for example. I haven’t done this either.