Presented at NIPS 2014 (PDF) by Dai, Olah, Le and Corrado.
Model
The authors consider a modified version of the PV-DBOW paragraph vector model. In previous work, PV-DBOW had distinguished words appearing in the context window from non-appearing words given only the paragraph vector as input. In this modified version, the word vectors and the paragraph vectors take turns playing the role of the input, and word vectors and paragraph vectors are trained together. That is, a gradient update is performed for the paragraph vector in the manner of regular PV-DBOW, then a gradient update is made to the word vectors in the manner of Skipgram, and so on. This is unfortunately less than clear from the paper. The authors were good enough to confirm this via correspondence, however (thanks to Adriaan Schakel for communicating this). For the purposes of the paper, this is the paragraph vector model.
The representations obtained from paragraph vector (using cosine similarity) are compared to those obtained using:
- an average of word embeddings
- LDA, using Hellinger distance (which is proportional to the L2 distance between the component-wise square roots)
- paragraph vector with static, pre-trained word vectors
In the case of the average of word embeddings, the word vectors were not normalised prior to taking the average (confirmed by correspondence).
Corpora
Two corpora are considered, the arXiv and Wikipedia:
- 4.5M articles from Wikipedia, with a vocabulary of size 915k
- 886k articles from the arXiv, full texts extracted from the PDFs, with a vocabulary of 970k words.
Only unigrams are used. The authors observed that bigrams did not improve the quality of the paragraph vectors. (p3)
Quantitative Evaluation
Performance was measured against collections of triples, where each triple consisted of a test article, an article relevant to the test article, and an article less relevant to the test article. While not explicitly stated, it is reasonable to assume that the accuracy is then taken to be the rate at which similarity according to the model coincides with relevance, i.e. the rate at which the model says that the relevant article is more similar than the less relevant article to the test article. Different sets of triples were considered, the graph below shows performance of the different methods relative to a set of 172 Wikipedia triples that the authors built by hand (these remain unreleased at the time of writing).
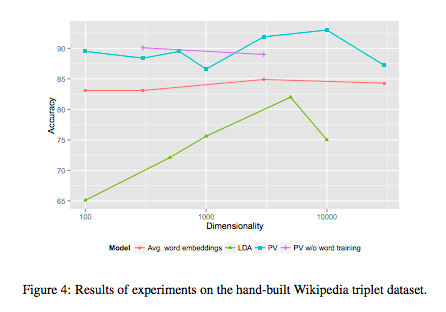
It is curious that, with the exception of the averaged word embeddings, the accuracy does not seem to saturate as the dimension increases for any of the methods. However, as each data point is the accuracy of a single training (confirmed by correspondence), this is likely nothing more than the variability inherent to each method. It might suggest, for example, that the paragraph vectors method has a tendency to get stuck in local minima. This instability in paragraph vector is not apparent, however, when tested on the triples that are automatically generated from Wikipedia (Figure 5). In this latter case, there are many more triples.
Performance on the arXiv is even more curious: accuracy decreases markedly as the dimension increases!
Implementations
I am not sure there are any publicly available implementations of this modified paragraph vectors method. According to Dai, the implementation of the authors uses Google proprietary code and is unlikely to be released. However it should be simple to modify the word2vec code to train the paragraph vectors, though some extra code will need to be written to infer paragraph vectors after training has finished.
I believe that the gensim implementation provides only the unmodified version of PV-DBOW, not the one considered in this paper.
Comments
It is interesting that the paragraph vector is chosen so as to best predict the constituent words, i.e. it is inferred. This is a much better approach from the point of view of word sense disambiguation than obtaining the paragraph vector as a linear image of an average of the word vectors (NMF vs PCA, in their dimension reductions on bag of words, is another example of this difference).
Thanks to Andrew Dai and Adriaan Schakel for answering questions!
Questions
- Is there is an implementation available in GenSim? (see e.g. this tutorial).
- (Tangent) What is the motivation (probabilistic meaning) for the Hellinger distance?
Interesting paper I hadn’t noticed before! The most impressive result to me is that when the doc-vecs and word-vecs are co-trained, you can use the word-vecs to navigate the doc-vec space. I’m a bit disappointed the authors don’t share all their training parameters – such as skip-gram window-size, frequent-word subsampling, and gradient-descent alpha-rates. Also, that they don’t mention whether the DM modes offers the same benefits – that already inherently co-trains word and doc vectors, and according to the PV paper is better for many purposes.
I’ve been working on improving the gensim Doc2Vec implementation, and my changes pending integration will allow its DBOW mode to co-train the word-vectors, by adding the `dbow_words=1` parameter. (In the abbreviated names I use in that code, I call this mode ‘dboww’ for DBOW + Words.) The patched word2vec.c+sentence-vectors example code that Tomas Mikolov once posted to the word2vec list always did this co-training, and only with this training do you also get usable word-vectors from DBOW, so it seemed natural to add even before seeing this paper.
However, in my experiments with the IMDB data from the original PV paper, such co-training sometimes makes the doc-vectors slightly *worse* at sentiment prediction – the actual effect is dependent on many parameter choices, including hierarchical-sampling vs negative-sampling, alpha, and number of training passes
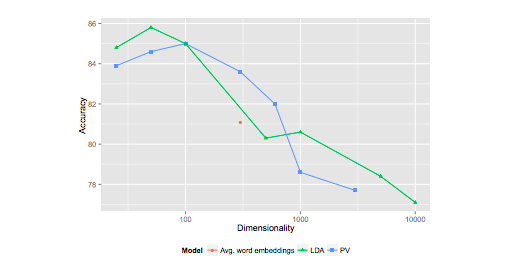
Further, looking closely at the graphs from this “Document Embedding with Paragraph Vectors” paper, I don’t think they’ve shown a unequivocally broad advantage for co-training. In figure 4 (hand-built dataset), PV without word co-training is better at some lower dimensions, then slightly worse over 1000 dimensions… then there’s no more comparison. In figure 5 (automated Wikipedia categories-based dataset), “without word training” is just slightly worse, at the two dimensionalities tested. So I suspect that rather than a general result, this superiority for word-co-training is dependent on dataset, task (doc-similarity vs sentiment, etc), and parameters.
Of course, the ability to use the word-vecs to add/subtract concepts from the doc-vecs may be so useful that even ‘worse’ doc-vecs are OK, to get that ability.
The sharp drop-off in PV performance on the arXiv dataset, for large dimensionality, may be because the model is essentially using all those free parameters to memorize other non-topic-related tricks for doing well on the word-prediction training task. Some vague rules-of-thumb that relate a corpus vocabulary, size, diversity, etc with an optimal set of PV parameters for topicality-uses might be possible with much more experimentation.
Is this a NIPS paper? I googled a while and found it’s listed in the first author’s google scholar profile as an arxiv paper.
Hi bigpalm, I wasn’t there myself, but is what on the website of the DL workshop at NIPS 2014 that I found the paper (see the almost invisible PDF link above). I haven’t asked the authors about this.
Thanks. Found it too. One question w.r.t. Paragraph Vector is, if we derive a paragraph embedding for each sentence in a document, how we are going to train the classifier for that document? Simply concatenating the embeddings is probably not good, since the order of sentences/embeddings is unimportant. The description in the experiment on IMDB in “Distributed Representations of Sentences and Documents” seems to suggest that they trained one vector for a whole review.