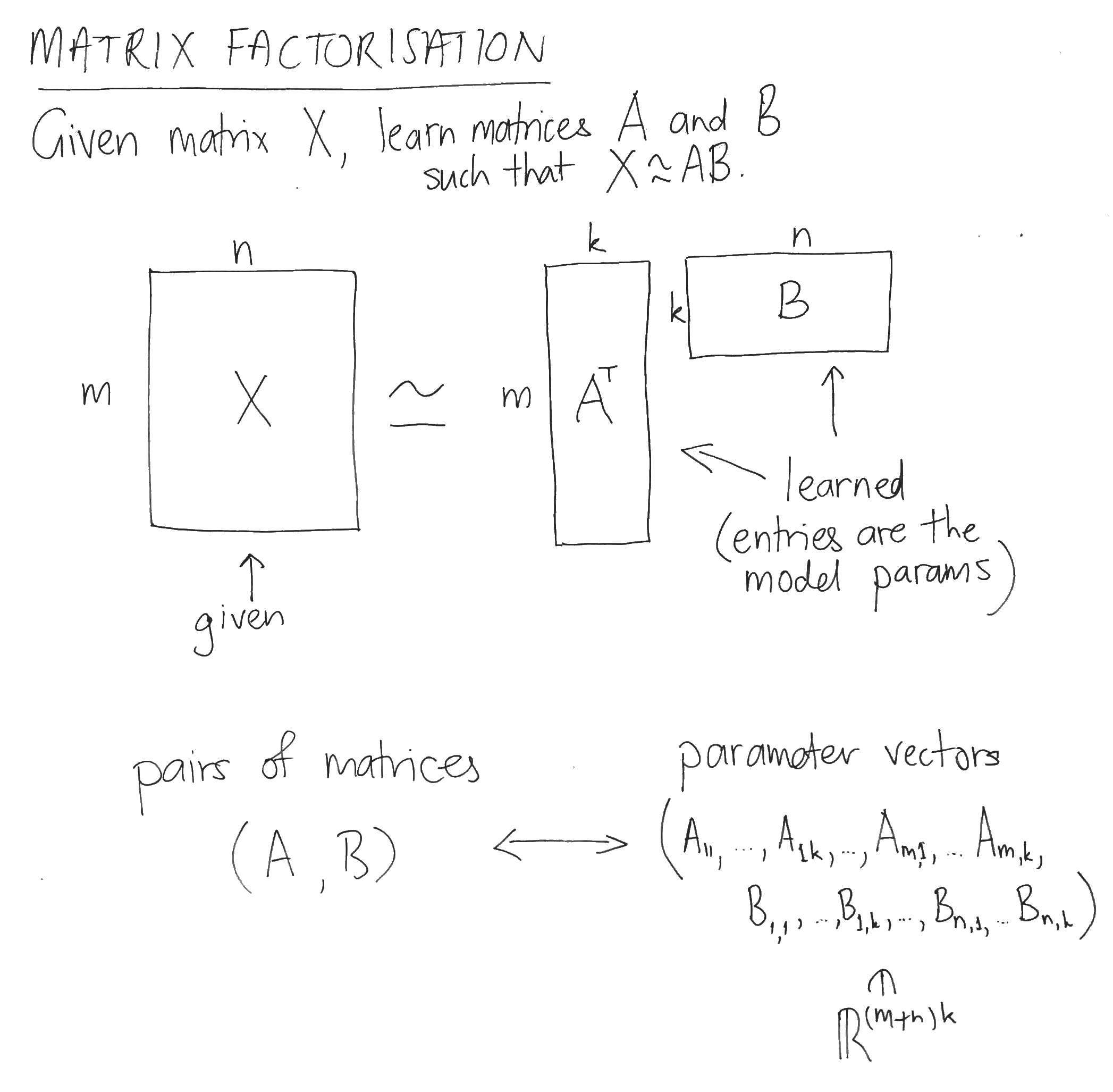
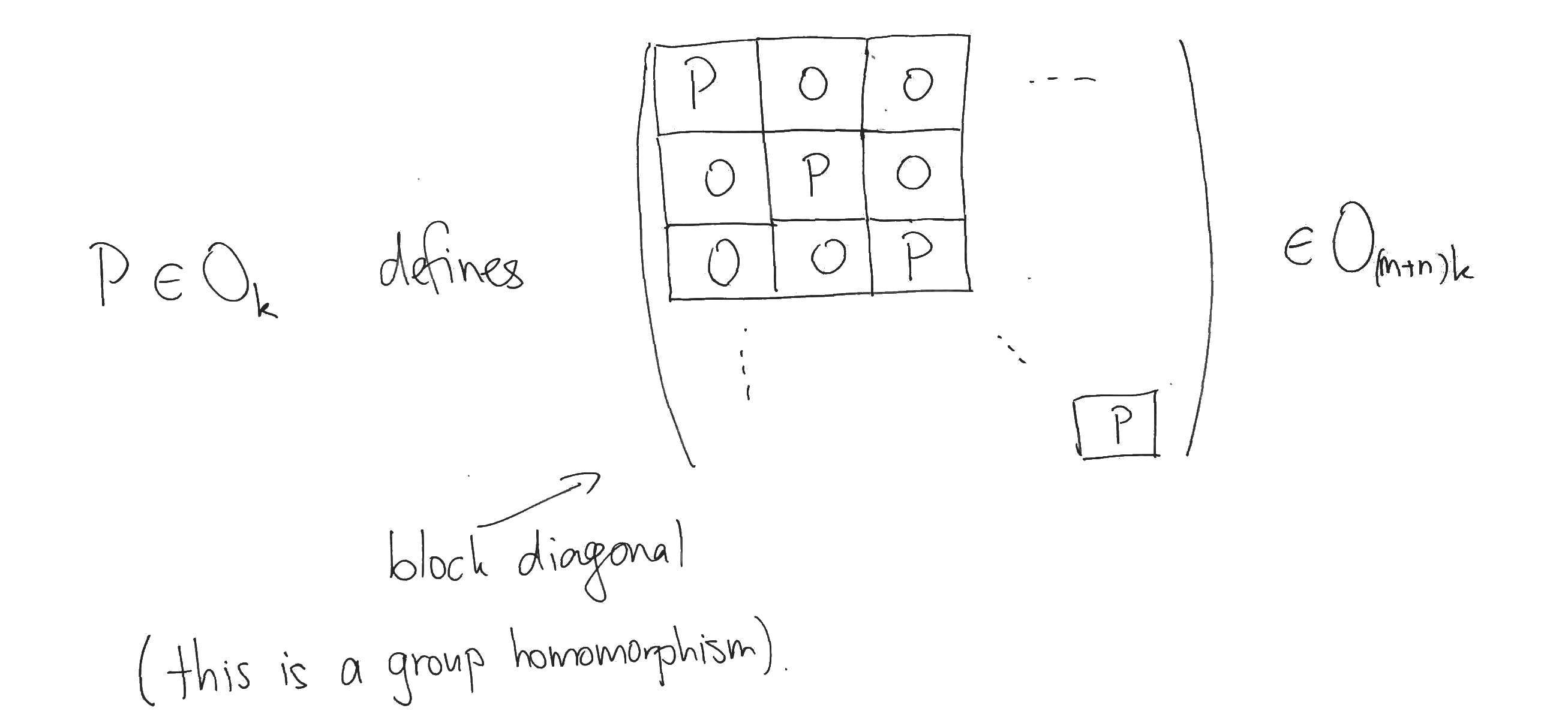
(The following thought experiment was suggested to me by my colleague Ryan Cao; mistakes and invective are my own).
FRI is often described as a “low degree test”, which suggests that the verifier should reject with high probability if the degree is high. This is not the case, as the simple example below demonstrates. Indeed it is the polynomials of highest degree that have the highest chance of being erroneously accepted by the verifier. (What is true is that the FRI verifier rejects with high probability if the evaluations are far from the code: FRI is a proof of proximity).
Let $\mathbb{F}$ be a field, $\Omega \subset \mathbb{F}$ with $n = |\Omega|$, and write
$$ \epsilon_\Omega : \mathbb{F}[x]^{<n} \to \mathbb{F}^\Omega, \qquad f \mapsto (f(\omega))_{\omega \in \Omega} $$ for the evaluation map. For any $k \leq n$, let $\text{RS}[\Omega, k] := \epsilon_\Omega (\mathbb{F}[x]^{< k})$ be the Reed-Solomon code of evaluations of polynomials of degree strictly less than $k$ on $\Omega$.
Henceforth we assume that $\Omega$ is a subgroup of the multiplicative group $\mathbb{F}^\times$ and that $n = |\Omega|$ is a power of two. The degree bound $k=2^d$ will also be a power of two. For $\alpha \in \mathbb{F}$, let $\Phi_\alpha : \mathbb{F}[x] \to \mathbb{F}[x]$ be the FRI folding operation (in the coefficient domain) and write $\Psi_\alpha = \epsilon_\Omega \circ \Phi_\alpha \circ \epsilon_\Omega^{-1}$ for the corresponding operation in the evaluation domain. Then it’s not hard to check that for any $v \in \mathbb{F}^\Omega$ and $\alpha \in \mathbb{F}$, we have $$\begin{equation}\textstyle \tag{Fold}\label{Fold} (\Psi_\alpha(v))_{\omega^2} = \frac{1}{2} (1 + \frac{\alpha}{\omega}) v_{\omega} + \frac{1}{2} (1 – \frac{\alpha}{\omega}) v_{-\omega} \quad \forall \omega \in \Omega.\end{equation}$$
FRI operates by iterated folding, using challenges provided by the verifier. The claim of the proximity of $v^{(0)} := v \in \mathbb{F}^\Omega$ to the code $\text{RS}[\Omega, 2^d]$ is reduced to the claim of the proximity of $v^{(1)} := \Psi_\alpha v^{(0)}$ to the code $\text{RS}[\Omega^2, 2^{d-1}]$ for some $\alpha \in \mathbb{F}$. This process is repeated until the claim is that $v^{(d)}$ is close to the code $\text{RS}[\Omega^{2^d}, 1]$, at which point the verifier queries $t$ entries from $v^{(d)}$ and checks if they all agree: if they do, it concludes that $v^{(d)}$ is (w.h.p.) close to its code, and hence that the original vector $v^{(0)}$ is (w.h.p.) close to the original code. Proving that FRI is indeed a good test of proximity is complicated. It is easy to show, however, that FRI is not (indeed never intended being) a reliable means of detecting polynomials of high degree, and that is what we’ll do here.
For any $\omega \in \Omega$, let $L_{\omega, \Omega}$ denote the Lagrange interpolation polynomial, i.e. $$ L_{\omega, \Omega} = \prod_{\substack{\omega’ \in \Omega \ \omega’ \neq \omega}} \frac{x – \omega’}{\omega – \omega’} \in \mathbb{F}[x].$$ Then $\text{deg} L = n – 1$, i.e. it has has maximal degree (given the size of the evaluation domain $\Omega$). Its evaluations, however, are “one-hot” at $\omega$ $$ v_{\omega, \Omega} := \epsilon_\Omega (L_{\omega, \Omega}) = (0, \dots, 0, 1, 0, \dots, 0) $$ and in this sense are maximally close to the code, while not being in the code (having Hamming distance $1$ from the zero codeword). It’s easy to see from \eqref{Fold} that $$ \Psi_\alpha(v_{\omega, \Omega}) = \frac{1}{2} (1 + \frac{\alpha}{\omega}) v_{\omega^2, \Omega^2} $$ i.e. that except with negligible probability (when $\alpha=-\omega$), the folding will also have Hamming distance 1 from its code $\text{RS}[\Omega^2, 2^{d-1}]$. Note, however, that the relative Hamming distance has doubled, since the size of the evaluation domain has halved.
So let’s set $v^{(0)} := v_{\omega, \Omega}$. Then after $d$ rounds of folding, $v^{(d)}$ is (except with negligible probability) non-zero in exactly one place, and its relative distance from the code $\text{RS}[\Omega^{2^d}, 1]$ (which consists of constant vectors) is $2^d / 2^n$ i.e. the rate $\rho$ of the original code. The verifier thus accepts with probability $(1 – \rho)^t$. Given that $\rho$ is typically close to zero (e.g. $2^{22-64}$) and $t$ is always small, this probability is close to $1$. For this reason, it is misleading (if commonplace) to describe FRI as a “low-degree test”: the polynomials $L_{\omega, \Omega}$, which have maximal degree are routinely accepted by the FRI verifier. Why? Because the evaluations of these polynomials are close (“proximal”) to the code. FRI is a proof of proximity, after all.