I recently needed to demonstrate this fact to an audience that I could not assume would be familiar with Riemannian geometry, and it took some time to find a way to do it! You can use the HyperRogue game, which takes place on a tiling of the Poincaré disc. The avatar moves across the Poincaré disc (slaying monsters and collecting treasure) by stepping from tile to tile. It is a pretty impressive piece of software, and you can play it on various devices for small change. Below are four scenes from the game. This image was taken from the interesting paper on HyperRogue by Kopczyński et al., cited at bottom.

As a proxy for proving that the growth rate was exponential, just count the number of tiles that were accessible (starting from the centre tile) in N steps and no less. This gives the sequence 1, 14, 28, 49, 84, 147, 252, 434, 749, … . Plotting this values gives evidence enough.
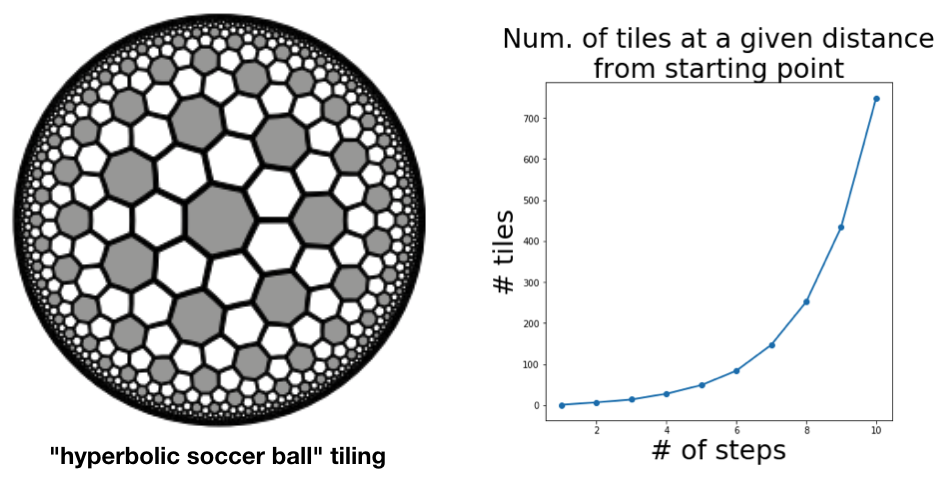
The authors of the paper do a more thorough job, obtaining a recurrence relation for the sequence and using this to derive the base of the exponential growth (which comes out at about $\sqrt{3}$.
[1] Kopczyński, Eryk; Celińska, Dorota; Čtrnáct, Marek. “HyperRogue: playing with hyperbolic geometry”. Proceedings of Bridges 2017: Mathematics, Music, Art, Architecture, Culture (2017).