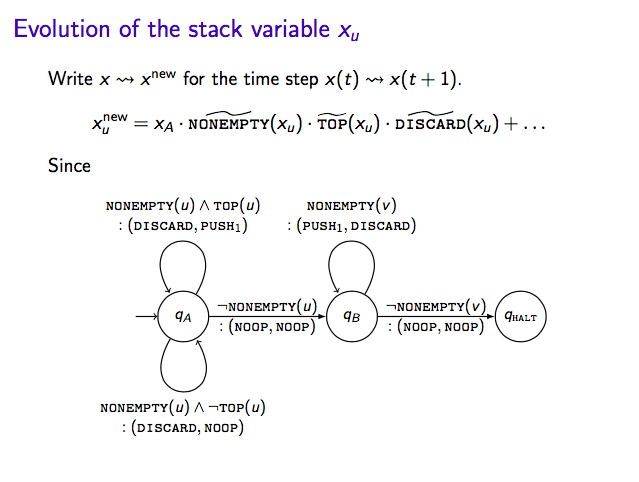
Here are the slides from a talk I gave the Sydney machine learning meetup on Siegelmann and Sontag’s paper from 1995 “On the Computational Power of Neural Nets”, showing that recurrent neural networks are Turing complete. It is a fantastic paper, though it is a lot to present in a single talk. I spent some time illustrating what the notion of a 2-stack machine, before focussing on the very clever Cantor set encoding of the authors.
There are also the following notes from a talk I gave at our Berlin ML seminar.